

1. 서 론
2. 방법론
2.1 LSTM(Long Short-Term Memory Model)
2.2 확률분포
3. 자료 구축
3.1 연구대상지
3.2 입력인자
3.3 자료 전처리
4. 결과 및 분석
4.1 민감도 분석
4.2 최적 분포
5. 결 론
1. 서 론
지난 109년간 우리나라의 계절별 강수량 변화를 살펴본 결과, 10년당 강수량 변화율이 +15.55 mm 증가한 여름철 강수량에 비해 겨울철 강수량은 약 –0.65 mm로 큰 변화를 나타내지 않았다(KMA, 2021). 연강수량은 최저 754 mm에서 최고 1,756 mm로 변화폭이 크므로 여름에는 홍수, 겨울과 봄에는 가뭄 피해가 빈번하게 발생하고 있으며 극한 홍수 및 가뭄 발생 빈도가 전망되고 있다. 또한 기온의 상승으로 인해 지표면 증발량이 더욱 증가하여 가용 수자원 확보에 대한 대비가 필수적인 상황이다. 특히 갈수기인 겨울과 봄에 가용수량이 부족하며 지역과 유역별로 편차가 심하기 때문에 효율적인 하천수 계획 수립이 마련이 필요하다. 국내에서는 물수지분석을 수자원장기종합계획을 통해 이용 가능한 수자원량을 예측하고 있다. 그러나 용수 수요량을 위치와 무관하게 일률적으로 행정구역별 유역면적비를 적용(Jang and Moon, 2022)하는 등의 수요량 산정의 문제점과 생 · 공용수의 일관적인 회수율 적용 방식(Oh et al., 2019) 등의 공급량 산정의 문제점이 존재한다. 이 중 회귀수량은 물 수요를 충족시킨 후 다시 하천으로 회귀되는 물의 양을 의미하고 생활 · 공업용수는 65%, 농업용수는 35%의 회귀율을 보여 회귀수량의 정확한 예측을 통해 효율적으로 하천수를 관리하는 것이 중요하다(Yoo et al., 2020; MOLIT, 2016). 따라서 본 연구는 Yoo et al.(2020)의 후속 연구로 기계학습을 통해 회귀수량 중 하수종말처리장의 방류량을 중기 예측(선행적으로 1달 수행)하였고 정확도 개선을 위해 방류량의 변동성 분포를 고려하여 입력자료로 활용하였다.
기계학습을 이용한 연구가 많이 진행되어 왔으며 주식 예측(Song et al., 2017; Lee, 2017; Kim et al., 2014), 경기 결과 예측(Kim and Kim, 2021; Seo et al., 2019; Kim et al., 2015), 질병 확산 예측(Arun et al., 2020) 등 다양한 분야에서 사용되었다. 수자원분야에서도 최근 기계학습을 통한 연구가 활발하게 이루어지고 있고 홍수 피해를 예방하기 위한 하천의 수위 예측 알고리즘 개발 연구가 주를 이루고 있다(Lee et al., 2021; Yoo et al., 2019; Jung et al., 2018; Tran et al., 2016). 기계학습의 기법 중 LSTM(Long Short-Term Memory) 기법을 사용하였는데 이는 시계열자료에 특화되어 있으며 기존 RNN(Recurrent Neural Network) 기법의 가중치 소실 문제를 보완하였다. Zhang et al.(2018)은 Elman, NARX, LSTM 기법으로 하수관 시스템을 모의한 결과, LSTM 기법이 가장 우수한 성능을 보였으며 Kim et al.(2019)은 RNN 기법에 비해 LSTM 기법이 유출량 모의 성능 연구에서 있어 더 정확도가 높다고 판단하였다. 그러나 Yoo et al.(2020)은 LSTM 기법이 극값에서 과대 및 과소 산정되는 경향이 있어 보완이 필요하다는 결과를 도출하였다.
따라서 본 연구에서는 청평댐 유역에 존재하는 하수종말처리장의 1달 후 방류량을 예측하기 위해 LSTM 기법을 활용하였으며 입력자료는 방류량을 포함한 수문자료를 사용하였다. 기존 연구에서의 한계점을 보완하기 위하여 1) 최신 데이터(2019~2020년)를 추가적으로 수집하여 학습 데이터의 양을 늘렸고 2) 시계열 자료로 구성되어 있는 입력자료의 특성 중 변동성을 파악하기 위해 통계특성을 고려하여 새로운 입력인자로 구축하였다.
2. 방법론
2.1 LSTM(Long Short-Term Memory Model)
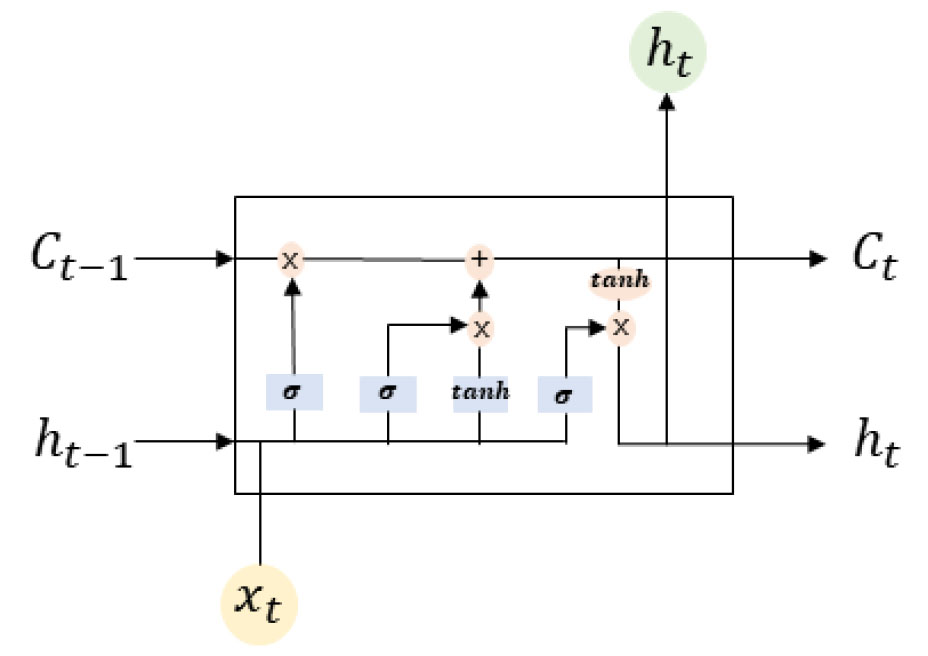
LSTM(Long Short-Term Memory) 기법은 RNN(Recurrent Neural Network) 기법 중 최적화 오류 문제를 보완한 기법으로 Hochreiter and Schmidhuber(1997)이 제안하였다. 또한 시계열 자료 처리에 특화되어 있어(Tran et al., 2016) 시계열 자료 예측에 많이 활용되고 있다. LSTM 기법은 입력 게이트(Input gate), 출력 게이트(Output gate), 망각 게이트(Forget gate)로 구성되어 있고 시간에 따른 상태를 유지하기 위한 셀의 데이터 이동을 조절한다(Fig. 1). 관련 식은 Eq. (1), (2), (3), (4), (5), (6)과 같다.
여기서 는 시그모이드 활성화 함수, 는 망각 게이트의 가중치, 는 새로운 출력 값, 는 입력값, 는 망각 게이트의 기울기, 나타낸다.
는 활성화 함수에 의해 생성된 새로운 셀 상태를 업데이트 시 사용하는 후보 셀, 는 후보 셀의 가중치, 는 후보 셀의 기울기를 나타낸다. 다음 단계인 입력 게이트()는 입력할 값을 결정하고 새로운 셀 상태를 업데이트한다. 는 현재의 셀 상태로 과거의 셀 상태인 과 후보 셀 로 이루어져 있다.
마지막 단계인 출력 게이트()는 무엇을 출력할지 결정하고 쌍곡탄젠트 함수를 이용해 새로운 출력 값()를 도출한다.
2.2 확률분포
2.2.1 Weibull 분포
Weibull 분포(Weibull distribution)는 연속확률 분포의 하나로, Weibull(1951)이 수명 검정 분석을 위해 고안한 분포로 고장 확률 밀도 함수를 나타내기 위해 제안하였다. Weibull 분포는 하한치가 0이고 일반적으로 오른쪽으로 왜곡되어 있는 형태를 보이므로 갈수량 또는 수명 데이터 분석에 자주 사용되고 있다. Weibull 분포의 확률밀도함수 형태는 Eq. (7)로 나타낼 수 있다. 여기서, 는 형상변수(>0), 는 축척변수(>0)이다.
2.2.2 Gumbel 분포
Gumbel 분포(Gumbel distribution)도 연속확률 분포의 하나로, Gumbel(1935)이 자료의 극치 중에서도 최대치에 해당하는 자료에 대한 분포를 표시하기 위해 발표하였다. Gumbel 분포는 연 최대홍수량 및 강우량자료의 분석에 많이 사용되고 있으며, Gumbel 분포의 확률밀도함수 형태는 Eq. (8)로 나타낼 수 있다. 여기서, 는 축척변수(>0)이고, 은 위치변수로 최빈값(mode)의 위치를 나타낸다.
2.2.3 Nomal 분포
Normal 분포(Normal distribution)는 Gaussian 분포 또는 표준오차곡선(normal error curve)이라 하며, 확률 및 통계분야에서 가장 중요한 분포이다. 일반적인 조건에서 독립확률변수들의 합이 커질수록 그 합의 분포는 Normal 분포에 가까워진다는 중심극한정리(central limit theorem) 때문이다. Normal 분포는 가설검정, 품질관리 등과 같은 통계분야 뿐만 아니라 수문분야에서도 많이 적용하는 분포이다. Normal 분포의 확률밀도함수는 Eq. (9)로 나타낼 수 있다. 여기서, 는 평균이고, 는 표준편차, 는 자료 값이다.
2.2.4 Generalized Extreme Value 분포
GEV 분포는 Gumbel 분포, Frechet 분포, Weibull 분포를 결합한 분포로 자료의 최대치 또는 최소치계열을 분석하는 경우에 많이 쓰이므로 수문분야에서는 홍수, 가뭄 등의 분석에 활용된다. 극치분포의 확률밀도함수는 Eq. (10)과 같다. 여기서, 는 축척변수, 는 형상변수, 은 위치변수를 나타낸다.
2.2.5 Gamma 분포
Gamma 분포는 왼쪽에서 경계를 갖고 오른쪽으로(양) 왜곡되어 있어 수문자료특성과 유사성을 가지고 있다. 따라서 연 최대홍수량, 갈수량 및 극대강수량 등의 확률분포를 나타내는데 사용되고 있다. Gamma 분포의 확률밀도함수는 Eq. (11), (12), (13)로 나타낼 수 있다. 여기서, 는 형상변수(>0), 는 축척변수(>0)이고 ~은 상수 값이다.
3. 자료 구축
3.1 연구대상지
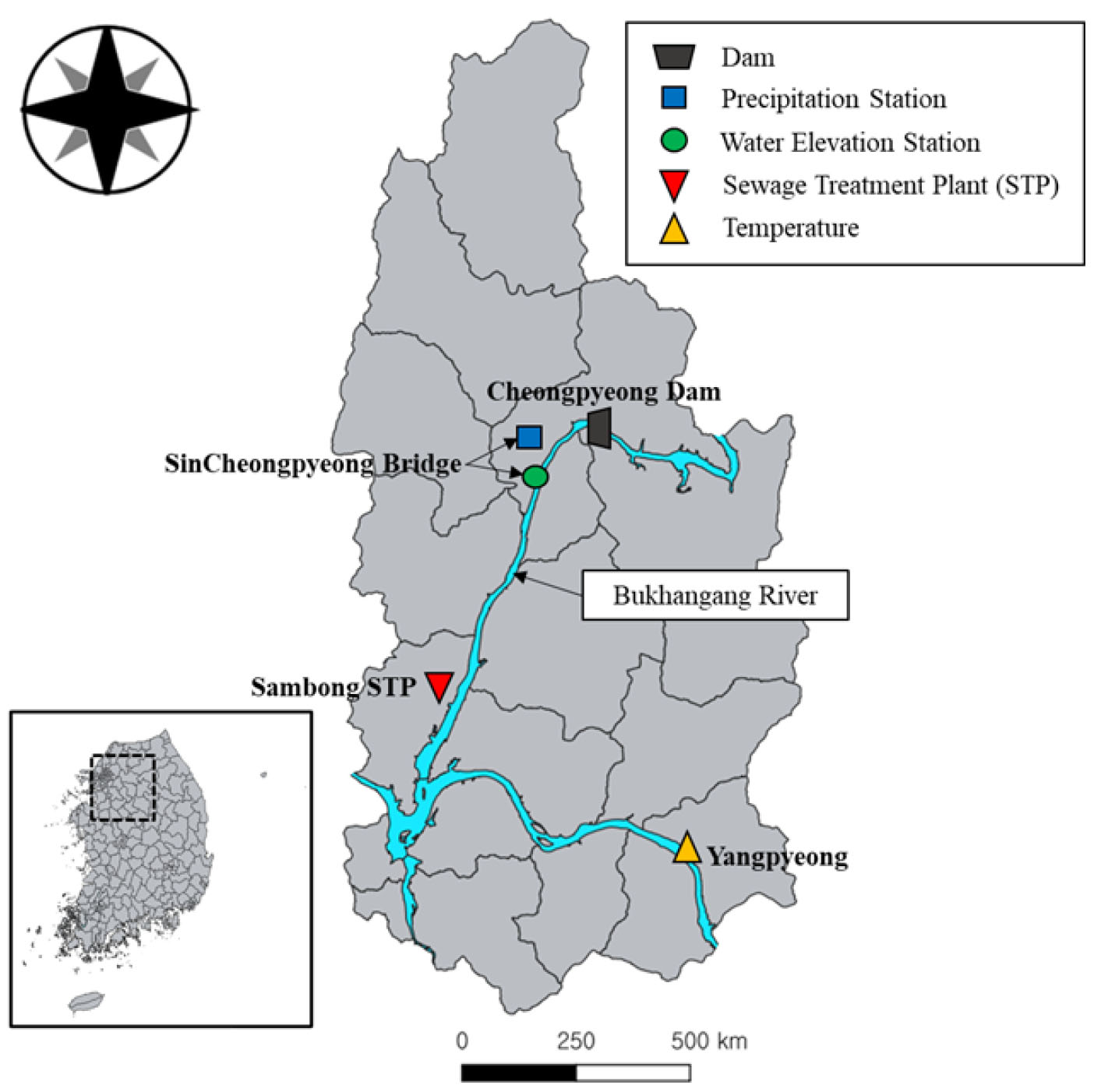
본 연구의 대상지는 청평댐 유역으로 북위 37°32'∼37°52', 동경 127°15'∼127°26'에 위치한다(Fig. 2). 2019년 기준 청평댐 유역의 총 인구는 180,970명으로 대부분 주거(53.84 km2), 농업(79.08 km2)용지로 사용하고 농업용수(53.7%), 생활용수(41.0%), 공업용수(5.3%) 순으로 용수를 이용하고 있다.
3.2 입력인자
방류량 예측 알고리즘에 사용된 기본 입력인자는 강수량(mm), 수위(EL.m), 유입량(m3/s), 방류량(m3/s), 기온(°C)으로 총 5가지이며 각각 한강홍수통제소, 국립환경과학원, 기상청에서 수집하였다. 입력인자는 모두 시계열 자료의 1일 단위이며 2012년~2020년(9년)의 자료를 연구기간으로 활용하였다. 입력인자의 지점, 단위, 보유 기관, 기간에 대해서는 Table 1에 나타내었다.
Table 1.
Information about input data
3.3 자료 전처리
수집한 입력인자를 방류량 예측 알고리즘에 적용하기 위해서 -test 및 -value를 통해 입력인자의 유효성을 검증하였다. -test는 2개의 집단에서 평균의 차이를 통해 통계적으로 유의미한 지 파악하기 위한 보편적인 방법으로 3가지 가정사항을 충족시켜야한다. 먼저, 수집된 데이터는 모두 같은 간격의 연속형 수치(identical interval and continuity)이어야 하며 둘째, 2개의 집단은 서로 독립적(independent)이어야 한다. 마지막으로 데이터의 수치는 정규성을 보여야 한다(normality). 또한 -value가 0.05 이하인 경우 유의미한 인자로 판단하여(Ruxton, 2006) 본 연구의 입력자료인 강수량, 수위, 유입량, 방류량, 기온을 대상으로 -test와 -value를 도출한 결과, 0.0 이하의 값이 도출되어 사용 가능함을 알 수 있었다(Table 2).
Table 2.
Results of t-test
| Input Data | P-value | Usage status |
| Precipitation (mm) | ~ 0.00 | Available |
| Water Elevation (EL.m) | ||
| Inflow (m3/s) | ||
| Outflow (m3/s) | ||
| Temperature (°C) |
또한, 방류량과 각 입력인자 간 상관관계를 판별하기 위해 상관성분석을 실행하였다. 일반적으로 상관성분석에서 많이 사용되고 연속형 변수의 상관관계를 측정하는 Pearson 상관계수()를 사용하였으며 Eq. (14)로 나타낼 수 있다. 여기서 , 는 , 의 평균을 의미한다.
입력 자료 중에 방류량과 관련이 없는 경우, LSTM 모형이 과거 자료로부터 학습할 때 교란 요인이 될 수 있기 때문에 입력인자로 사용할 수 없으며 분석결과는 Table 3와 같다. Pearson 상관계수()는 –1 ~ +1 사이의 값으로 일반적으로 0.1~0.3은 약한 양적 선형관계, 0.3~0.7은 뚜렷한 양적 선형관계, 0.7~1.0은 강한 양적 선형관계를 나타낸다. 강수량과 수위는 약한 양의 상관성, 유입량은 매우 강한 상관성, 기온은 강한 상관성을 나타내는 것을 알 수 있어 모두 입력인자로 사용하였다.
4. 결과 및 분석
4.1 민감도 분석
방류량 예측 알고리즘의 실제 모의 수행에 앞서 최적의 매개변수 값을 적용하기 위해 민감도 분석을 실시하였다. 선정한 매개변수는 총 4가지로 시퀀스 길이(Sequence Length), 반복횟수(Iteration), 은닉층(Hidden Layer), 학습률(Learning Rate)이다. Table 4에는 매개변수별 고정값을 표기하였으며 예측자료의 정확도를 판단하기 위해 오차지표인 RMSE, MAE, IOA, R2로 평가하였다. 입력자료는 9년간의 수문자료를 사용하였으며 예측자료는 1달 후의 방류량으로 설정하였다.
Table 4.
Test cases for sensitivity analysis
| Parameter | Setting Value | Evaluation |
| Sequence Length | 1, 5, 10*, 20 |
RMSE, MAE, IOA, R2 Comparison |
| Iteration | 100, 1000*, 10000, 50000 | |
| Hidden Layer | 1, 2*, 5, 10 | |
| Learning Rate | 0.005, 0.01*, 0.05, 0.1 |
각 매개변수별로 민감도분석을 실행한 결과 오차지표 비교를 통해 시퀀스 길이 5일, 반복횟수 10000번, 은닉층 5개, 학습률 0.05가 최적값으로 선정되었다. 해당 결과를 Table 5에 표기하였으며 향후 방류량 예측 알고리즘 수행 시에 해당 값으로 적용하였다.
Table 5.
Results of Sensitivity Analysis
4.2 최적 분포
본 연구에서 사용한 입력인자는 시계열 자료로 변동성을 가지는 특징이 있다. 방류량 자료의 변동성을 확인하고 새로운 입력인자로 사용하기 위해 변동성분에 대한 분포를 Eq. (15)으로 도출하였다.
여기서, 는 새로운 입력인자로 사용하기 위한 최적분포 값이며 는 일반적으로 확률분포로 많이 사용되는 Normal 분포, Gumbel 분포, Gamma 분포, Weibull 분포, Generalized Extreme Value(GEV) 분포를 활용하였다. 는 Matlab(version, R2020b)을 이용하여 방류량 자료의 최적 분포형태를 비선형 회귀 모델 피팅(fitnlm) 라이브러리 및 카이제곱 검정(chi-squared test)을 통하여 선정하였으며 관측값과 확률 분포 간 잔차(residual)의 경우, 실제 자료 분석을 통하여 복합삼각함수 형태로 도출하였다(~는 상수, Eq. (16)). Table 6은 확률분포를 고려하지 않은 경우와 5가지의 확률분포와 잔차를 고려한 경우의 오차정도에 대해 비교하였다. 그 결과, 변동성 분포를 고려한 경우가 고려하지 않은 경우에 비해 정확도가 높게 나타났으며 정규분포 형태의 오차지표가 가장 최소로 도출되었다.
Table 6.
Comparison of Distribution
관측값과 변동성분포 중 정규분포를 입력자료로 고려한 경우와 고려하지 않은 경우의 모형 예측값을 Fig. 3에 제시하였다. 변동성을 입력자료로 활용하였을 때 방류량이 적은 경우가 많은 경우에 비해 정확도가 높음을 알 수 있었다. 변동성 고려유무에 따라 산포도를 비교해본 결과(Fig. 4), 변동성을 고려하지 않은 예측값이 관측값에 비해 72.2%(239개), 변동성을 고려한 예측값이 관측값에 비해 57.7%(191개)가 과대 산정된 것을 파악할 수 있다. 변동성을 고려한 경우가 고려하지 않은 경우에 비해 적게 과대 산정되는 원인으로는 정규분포의 형태가 계절성을 간접적으로 재현했기 때문이라고 판단된다. 따라서 시계열 데이터의 자기상관성을 파악하기 위한 함수인 자기상관함수를 통해 정규분포의 고려 유무에 따른 방류량 예측 결과를 비교해보았다. Fig. 5는 변동성 고려 유무에 따른 예측된 방류량의 자기상관성을 나타내며 모두 시계열 데이터이므로 시차가 증가할 때 ACF 값이 감소하는 경향을 보인다. 또한 정규분포를 고려하여 입력인자로 사용한 경우가 그렇지 않은 경우에 비해 계절에 따라 고정된 주기가 변화하여 나타나는 Scalloped shape이 보다 뚜렷한 것으로 판단된다(Hyndman and Athanasopoulos, 2018). 따라서 정규분포의 형태를 고려한 경우 계절성의 영향을 더 받는 것을 확인할 수 있다.
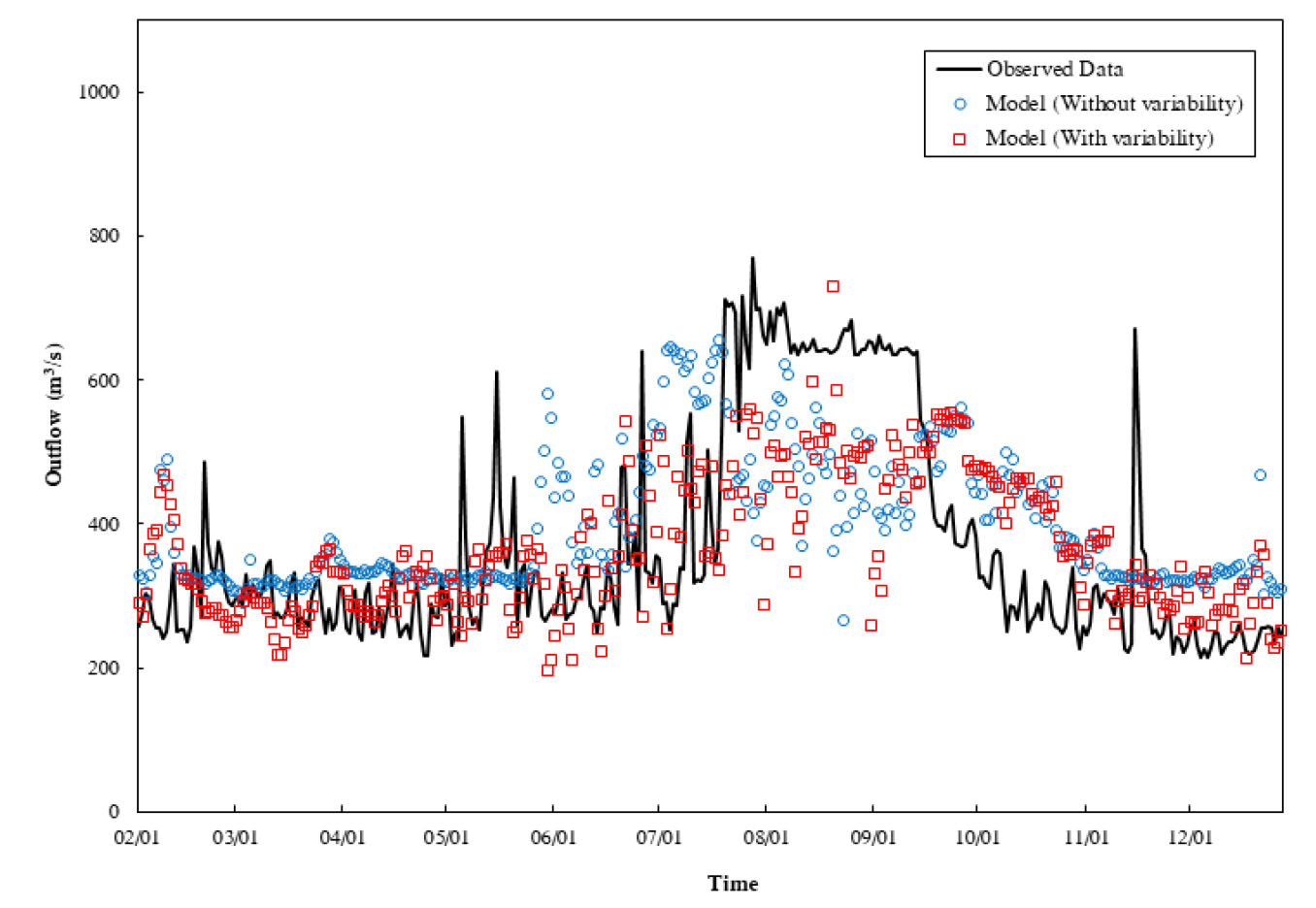
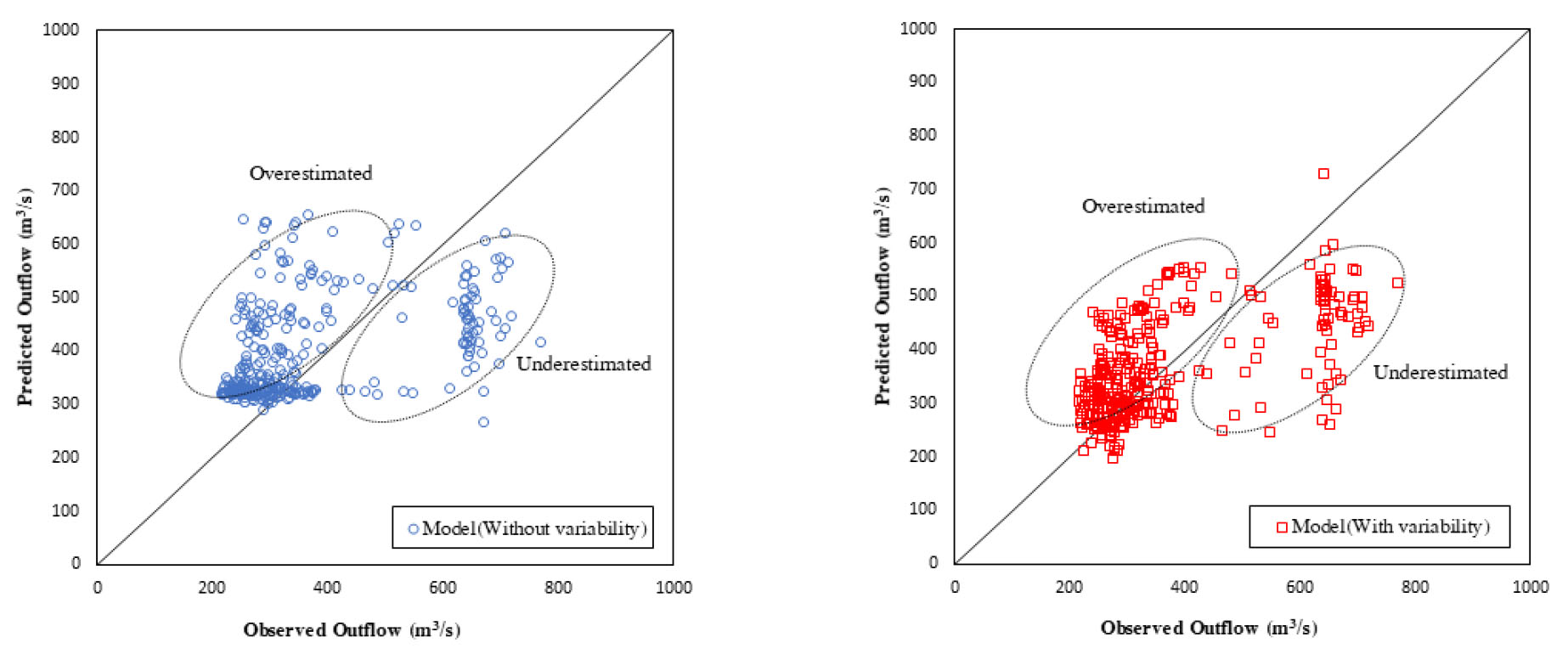
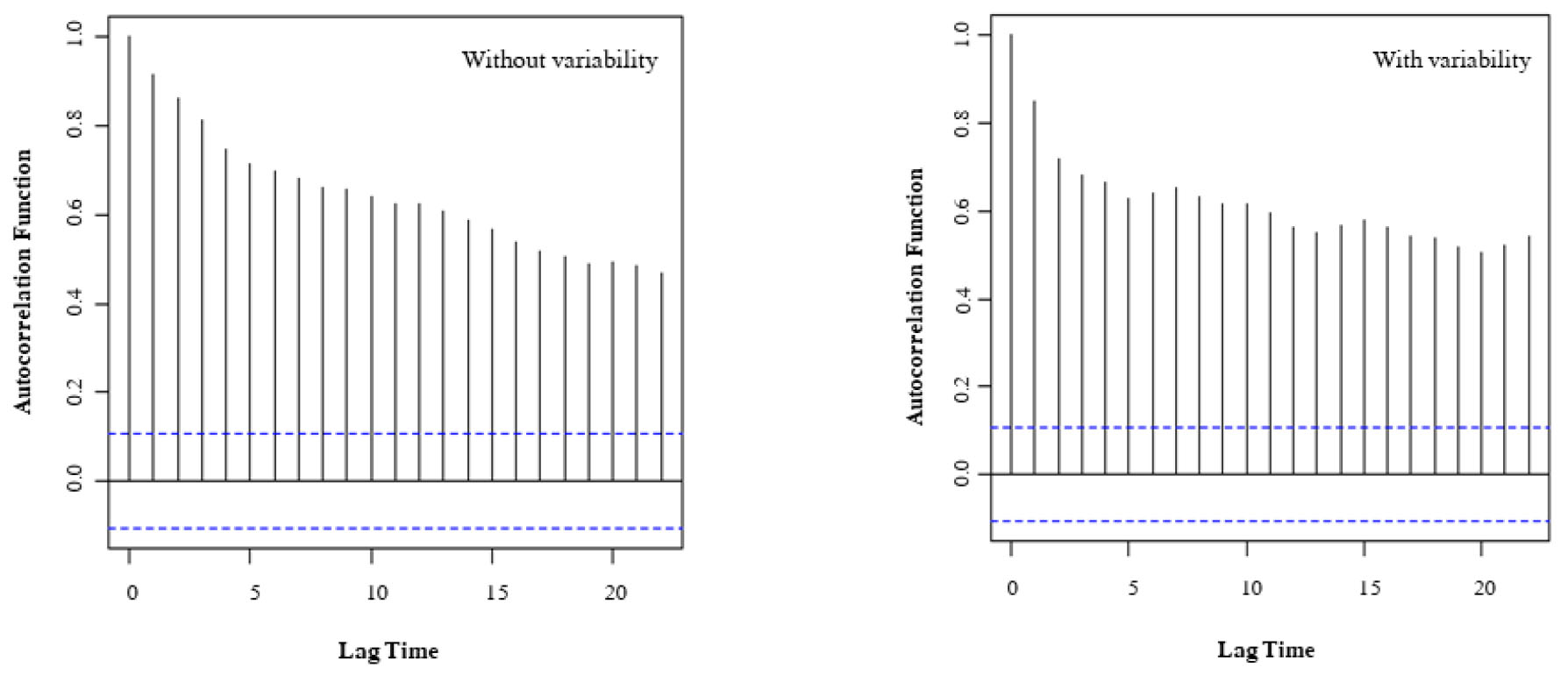
회귀수량의 정확한 예측은 가뭄이나 갈수기에 가용수량을 파악하기 위해 수행되기 때문에 방류량의 값이 과대산정이 되면 재이용수로 사용되는 양에 영향을 미치게 되어 용수부족 현상이 발생할 수 있다. 따라서 변동성 분포를 입력자료로 함께 고려할 경우, 그렇지 않은 경우에 비해 정확도가 향상이 된 것으로 보아 효율적인 하천수 계획 수립에 있어 필요하다고 판단된다.
5. 결 론
본 연구는 가뭄 등으로 인한 용수부족 현상을 대비하기 위하여 기계학습을 통해 회귀수량 중 하수종말처리장 방류량을 예측하고자 하였다. 연구대상지는 남양주시에 위치한 삼봉하수종말처리장으로 사용한 입력인자는 방류량, 유입량, 강수량, 수위이며 모두 1일 단위이다. 학습기간은 2012년~2019년, 수행기간은 2020년, 예측 결과는 1달 후 방류량으로 설정하였다. 기계학습 모형도 시계열 자료에 특화되어 있는 LSTM 모형을 활용하였고 입력인자를 입력자료로 활용하기 위해 t-test, 상관성분석으로 검증하였으며 민감도분석을 통해 매개변수의 최적값을 도출하는 등의 모형을 구축하였다.
추가적으로 보다 정확한 예측 결과를 위해 방류량 자료의 변동성 분포도 입력인자로 고려하였다. 변동성 분포를 도출하기 위해 5가지의 분포(Normal 분포, Gumbel 분포, Gamma 분포, Weibull 분포, GEV 분포) 중 최적의 분포형태와 복합삼각함수 형태의 관측값과 분포 사이 잔차를 합한 식을 가정하였다. 오차정도를 통해 비교한 결과, Normal 분포가 가장 최적의 분포로 판단되었고 최종적으로 변동성 분포를 입력인자로 고려한 경우가 그렇지 않은 경우에 비해 오차지표인 MAE가 15.8 m3/s, RMSE가 6.95 m3/s 만큼 감소하였다. 특히 가용수량이 부족한 봄과 겨울에 변동성 분포를 고려하지 않은 경우가 더 과대산정되는 경향을 보였고 회귀수량을 재이용하기 위한 하천수 계획 수립에 있어 변동성 분포를 고려하는 경우가 보다 합리적인 관리체계를 수립할 것으로 예상된다.
그러나 극값 주변에서는 과소산정되는 결과를 확인하였다. 이는 LSTM 기법의 구조적인 문제와 급격한 강수량 변화로 인해 발생되었다고 판단된다. 이러한 문제를 해결하기 위해서 1) 용수이용량의 검토, 2)입력인자의 단위 축소, 3) 입력자료 전처리 고도화, 4) 변동성의 세분화 등을 고려하면 예측 방류량의 정확도를 개선시키고 최종적으로는 하천수 이용 계획을 수립하기 위한 자료로 활용될 것으로 기대된다.
