

1. 서 론
최근 구조물의 장기 안전성 확보와 유지관리 효율 향상을 위해 구조건전성 모니터링(SHM)기술의 적용이 급격히 확대되고 있고 인공지능 및 디지털 센서 기술의 발달로 교량, 터널, 고층건물 등 다양한 인프라 구조물을 대상으로 한 구조 건전성 모니터링 시스템(SHMS)이 폭넓게 적용되고 있다. 국토안전관리원이 구축, 운영중인 특수교량 통합 유지관리 시스템(LOBMAC)과 같이 SHMS는 구조물이 설치된 현장 환경요인 또는 구조 자체적인 요인들로 인해 발생하는 구조물의 거동을 상시적으로 모니터링 하여 실시간으로 구조물의 상태를 계측, 분석함으로써 구조물에 발생할 수 있는 잠재적 손상이나 성능 저하를 조기에 감지하여 유지관리의 효율을 재고할 수 있는 핵심도구로 부상하고 있다.
SHMS의 센서 네트워크는 구조물의 현재 거동상태와 장기적 경향을 분석, 예측할 수 있도록 구축되는데. 통신 불안정, 전원불량, 센서 노후화, 환경적 요인에 의한 계측 데이터의 신호 드리프트, 손실, 노이즈 혼입 등의 다양한 결함(Fault)이 발생하여 구조물 상태 진단의 신뢰성을 저하시킬 수 있어 구조물 이상상태 판정에 오류를 일으키는 위험요인으로 작용한다. 그러므로 결함 검출(Fault Detection)은 SHMS 전 단계에서 수행되어야 하는 데이터 품질관리의 필수과정이라 할 수 있다.
본 연구에서는 구조건전성 모니터링 데이터의 결함 검출 기법을 데이터 중심기법(Data-driven Approach)과 시스템 중심 기법(Model-based Approach)으로 구분하여 고찰하고, 주요 알고리즘 특성을 분석함으로써 결함 검출 기법의 실무 적용 가능성과 향후 발전 방향을 제시하고자 한다.
2. 본 론
2.1 데이터 결함 검출의 정의
결함(Fault)은 데이터 처리 과정에서 예상치 못하게 발생하는 비정상적인 데이터 상태를 의미하며 이러한 데이터 결함은 시스템 전체의 모니터링 성능을 저하시키는 주요 요인으로 작용한다. SHMS에서의 데이터 결함은 다음과 같은 형태 등으로 나타난다.
• 센서 고장(Sensor Failure): 계측장비의 하드웨어 손상으로 신호가 완전히 소실되는 경우
• 신호 드리프트(Signal Drift): 센서 출력이 시간에 따라 서서히 변동하는 비정상적 현상
• 데이터 손실(Missing Data): 통신 오류, 저장 실패로 특정 구간 데이터가 존재하지 않는 상태
• 이상 노이즈(Abnormal Noise): 외부 전자파, 진동, 온도 변화 등에 의해 신호가 왜곡되는 경우
• 시스템 오류(System Fault): DAQ나 네트워크 노드의 동기화 실패, 시간 동기화 불일치 등
결함 검출(Fault Detection)은 이러한 이상 상태를 조기에 탐지하여 신뢰성 있는 데이터만을 모니터링 해석에 활용하기 위한 과정으로서 일반적으로 다음의 3단계로 구성된다.
• 데이터 전처리(Preprocessing): 이상치 제거, 필터링, 결측치 보정 등 데이터 품질 향상 단계
• 결함 탐지(Detection): 통계적 지표나 학습 모델을 이용하여 비정상 패턴을 판별
• 결함 분류(Classification) 및 복원(Recovery): 결함 유형별 원인 진단 및 정상 데이터 복원
위 과정은 SHMS의 데이터 신뢰성 확보를 위한 핵심 절차이며, 결함 검출 결과는 손상탐지(Damage Detection)나 예측진단(Predictive Maintenance)의 정확도에 직접적인 영향을 미친다. 결함의 원인은 전술한 바와 같이 현장에 설치된 시스템 하드웨어 또는 소프트웨어의 기능적 오류로 인해 발생할 수 있으며, 이러한 시스템 결함으로 발생한 데이터 왜곡 및 손실은 장기적으로는 구조물의 수명 저하, 구조물 성능저하로 인한 인적, 물질적 손실 등을 야기할 수 있다. 따라서 결함 검출을 수행하여 모니터링 시스템에서 발생하는 결함에 신속하게 대응해야 한다.
2.2 결함의 분류 및 검출 절차
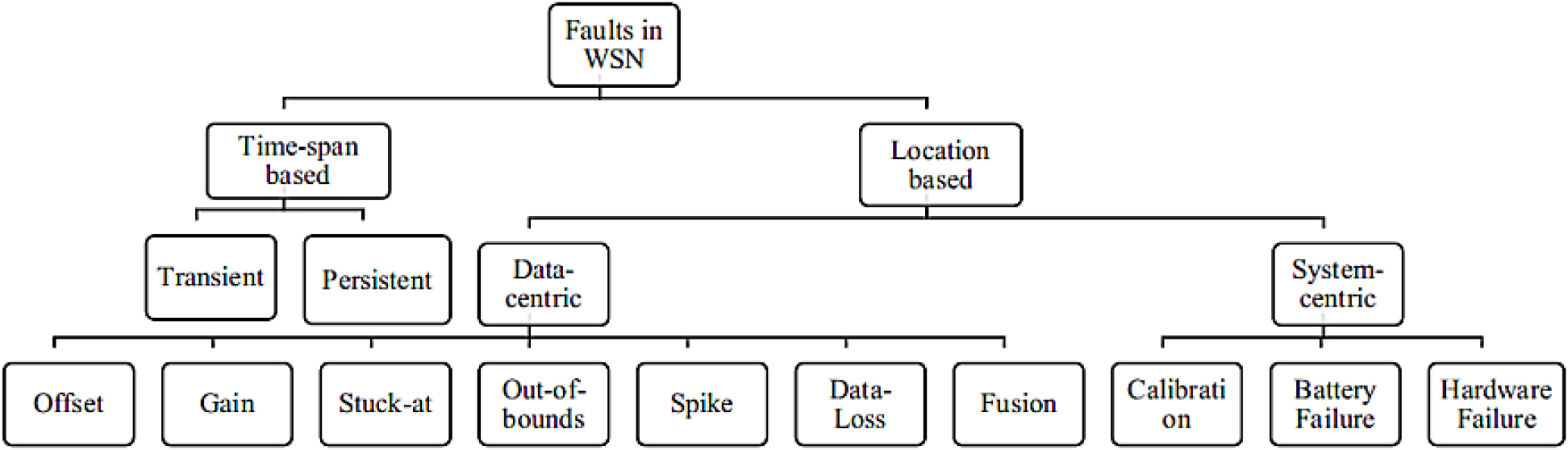
SHMS 데이터의 결함은 일반적으로 결함시간과 결함위치 두 가지 관점에서 분류될 수 있는데 결함시간 관점에서의 결함은 결함의 지속성을 의미하여 지속적 결함과 일시적 결함 두 가지 범주로 분류가 가능하다(Kim, 2021) 일시적인 결함의 경우 네트워크 장애, 환경적 요인에 따른 단기간, 일회성 결함의 발생으로 정의할 수 있으며 이러한 경우 결함은 영구적으로 존재하지 않아 해당 시점 후 그 발생 요인이 소멸한다. 지속적인 결함의 경우는 시스템 장애 장비의 이상 등으로 발생할 수 있으며 이러한 결함은 적극적 조치가 수행될 때 까지 결함이 지속적으로 발생할 수 있다. 결함위치 관점에서 분류한 결함은 Table 1에서 보는 바와 같이 크게 데이터 중심 기법(Data-driven Approach)과 시스템 중심 기법(Model-based Approach)로 구분할 수 있으며 최근에는 이를 결합한 하이브리드 형태로 그 방식이 진화하고 있다.
Table 1.
Fault detection classification methods
2.2.1 데이터 중심 기법(Data-driven Approach)
데이터 중심 기법은 물리적 모델링을 수행하지 않고 관측 데이터 자체의 통계적 특성과 상관관계를 이용하여 결함패턴을 분류, 검출하는 방식이다. 이 기법은 빅데이터 및 인공지능 기술의 발전과 함께 빠르게 확산되고 있으며 다수 센서로부터 수집된 시계열 데이터를 분석하여 비정상 상태(anomaly)를 식별할 수 있다. 데이터 중심 기법을 통해서 Fig. 1과 같이 다양한 범주로 결함 분류가 가능하다.
(1) 통계적 접근법(Statistical Approach)
데이터의 평균, 분산, 공분산 등을 활용하여 정상 구간과 비정상 구간을 구분한다. 대표적으로 Mahalanobis Distance, Hotelling’s T2 통계량, Grubbs Test, Control Chart(Shewhart, CUSUM, EWMA) 등이 있다. 이 방법은 계산이 간단하고 실시간 적용이 용이하나, 데이터 분포가 비정상적이거나 노이즈가 큰 경우 정확도가 저하될 수 있다.
(2) 차원 축소 기반 접근법(Dimensionality Reduction)
고차원 센서 데이터의 상관관계를 분석하기 위해 PCA(Principal Component Analysis), ICA(Independent Component Analysis), LDA(Linear Discriminant Analysis) 등이 적용된다. PCA 기반 결함 검출은 정상상태 데이터로부터 주요 주성분을 추출한 후, 잔차 공간(residual subspace)의 변화를 감시함으로써 이상 상태를 탐지한다.
(3) 머신러닝 기반 접근법(Machine Learning-based Approach)
정상 데이터와 비정상 데이터를 학습시켜 분류 또는 회귀 문제로 결함을 검출한다. 지도학습(Supervised Learning) 기법으로는 SVM(Support Vector Machine), Decision Tree, Random Forest, Gradient Boosting 등이 활용되며, 비지도학습(Unsupervised Learning) 기법으로는 K-means Clustering, DBSCAN, Autoencoder, Isolation Forest 등이 널리 사용된다. 특히 오토인코더(Autoencoder)는 입력 데이터를 저차원 잠재공간으로 압축한 후 복원하며, 정상 상태에서는 복원오차가 작고 결함 상태에서는 오차가 급증하는 특징을 이용한다. 복원오차 는 다음과 같다.
(4) 시계열 기반 접근법(Time-series Modeling)
ARIMA, LSTM, GRU와 같은 시계열 예측 모델을 이용하여, 예측값과 실제값 간의 잔차를 비교함으로써 결함 여부를 판단한다. 딥러닝 기반 LSTM(Long Short-Term Memory) 네트워크는 시간 의존성이 강한 진동 신호나 하중 데이터의 이상 탐지에 효과적이다.
2.2.2 시스템 중심 기법(Model-based Approach)
시스템 중심 기법은 구조물의 물리적 거동 특성을 수학적으로 모델링하고, 실제 계측 데이터와 모델 예측치를 비교하여 결함을 검출하는 방법이다. 이 방법은 구조공학적 해석에 근거하므로, 물리적 해석이 가능하고 결함의 원인을 구조적 측면에서 설명할 수 있다는 장점이 있다.
(1) 파라미터 추정 기반 기법(Parameter Estimation)
구조물의 질량, 강성, 감쇠 등의 동적 파라미터를 추정하고, 시간에 따른 변화율을 분석하여 이상 여부를 판단한다.
예를 들어, 고유진동수의 변동이 일정 수준을 초과하면 구조적 결함이 존재할 가능성이 높다고 판단한다.
(2) 상태공간 모델(State-Space Model)
시스템 상태변수(state vector) 기반 예측값 산출과 실제값과의 차이를 잔차(residual)로 계산하여 결함을 검출한다.
여기서, 는 상태변수, 는 관측값, A, B, C는 시스템 행렬, , 는 노이즈를 나타낸다. 잔차 의 통계적 변화를 감시하여 결함 여부를 판정한다.
(3) 칼만필터 기반 진단(Kalman Filter-based Diagnosis)
센서 결함에 대한 실시간 보정 기능을 갖춘 대표적 알고리즘으로, 시스템 모델과 관측 데이터의 불확실성을 최소화하는 최적 추정법이다. 결함 발생 시 필터의 잔차 분포가 급격히 증가하므로, 이를 이용해 결함을 감지할 수 있다.
(4) 옵저버(Observer) 기반 결함 검출
루엔버거 옵저버(Luenberger Observer), 파리티 공간(Parity Space) 기법 등을 사용하여 입력-출력 간 관계를 실시간 추정한다. 센서의 오차나 노이즈가 시스템의 예상 응답과 일치하지 않을 때 결함으로 판정된다.
최근 연구에서는 두 접근법의 장점을 결합한 하이브리드 기법이 제안되고 있는데 예를 들어 칼만필터를 활용한 노이즈 처리 후 오토인코더를 활용한 잔차 특성의 학습하는 방식 등이 주목받고 있다.
2.2.3 결함 검출 절차
결함 검출 알고리즘은 일반적으로 전처리 → 추출 → 결함판정 → 후처리 단계를 거쳐 수행된다.
(1) 전처리(Preprocessing)
센서 데이터의 노이즈 제거, 결측치 보정, 정규화(Normalization) 등의 절차라 수행되는 과정으로서 FFT 기반 주파수 필터링, Savitzky-Golay필터, Gaussian smoothing 등이 자주 사용된다.
(2) 추출(Extraction)
Table 2에서 제시된 것 같이 시간영역(Time-domain), 주파수영역(Frequency-domain), 시간-주파수영역(Time-Frequency domain)에서 다양한 특징(Feature)을 추출한다.
Table 2.
Feature Extraction
(3) 결함판정(Fault Decison)
결함판정 절차에서는 특징 벡터를 기반으로 임계값을 설정하거나, 분류모델(Classifier)을 이용하여 결함 여부를 판정한다. 대표적인 판정 방식은 Table 3과 같다.
Table 3.
Fault detection methods
(4) 후처리 및 시각화(Postprocessing & Visualization)
검출된 결함 신호를 시간축 혹은 구조물의 위치좌표에 매핑하여 시각화함으로써 직관적으로 이상 상태를 파악할 수 있도록 한다. 실시간 대시보드는 클라우드 기반 플랫폼에서 구현가능하며, 이벤트 발생 시 자동 알림을 제공한다.
2.3 결함 검출 알고리즘
전술한 검출 절차를 통해 수행되는 결함 검출을 위한 알고리즘들이 존재하는데 결함의 특징상 학습 데이터(Training data set)를 확보하는 것이 어려워 규칙기반(Ruls based), 군집화 계열(Clustering based), 또는 패턴 검지형(Pattern detection) 알고리즘을 하나 또는 복수 이상으로 조합하는 방식을 사용한다(Kim, 2021). 본 연구에서 고찰한 알고리즘은 Table 4에 제시된 것과 같이 크게 통계적 기법(Statistical Methods), 모델기반 기법(Model-based Methods), 데이터기반 기법(Data-driven Methods), 그리고 하이브리드 결합형 기법(Hybrid Methods)으로 분류하였다(Farrar and Worden, 2012).
Table 4.
Fault detection algorithms
2.3.1 통계적 결함 검출 기법(Statistical Falut Detection)
(1) Hotelling’s 검정
다변량 데이터의 이상치를 탐지하기 위한 전통적 통계적 방법으로, 정상 데이터의 평균 벡터 µ와 공분산 Σ를 이용하여 정의되며(Chandola et al., 2009), 임계값()은 자유도 와 유의수준 𝛼에 따라 다음과 같이 결정된다:
Hotelling’s 는 구조물의 진동, 변형률 등 다변량 입력 신호에서 이상치 탐지에 효과적이다(Feng et al., 2014).
(2) EWMA(Exponentially Weighted Moving Average)
시간에 따른 드리프트 결함을 감지하기 위해 EWMA 필터가 사용된다.
해당 기법은 센서의 점진적 드리프트, 온도·습도 영향, 신호 변동 완화에 유리하다(Ghorbel et al., 2015). Table 5에서는 위에 제시된 필터에 대한 장·단점에 대해서 제시하였다.
Table 5.
Statistical Fault detection algorithms
| Methods | Pros | Cons | Apply |
| Simple calculation, Real-time | Limitation on nonlinear data | Vibration Strain | |
| EWMA | Drift detection | Low sensitivity for rapid fault | Temperature Incline |
2.3.2 모델기반 결함 검출(Model-based Fault Detection)
모델기반 기법은 시스템의 물리적 상태방정식을 기반으로 예측치와 관측치 차이를 분석한다(Farrar and Worden, 2012).
(1) 시스템 모델
(2) 칼만 필터 알고리즘(Kalman Filter)
칼만 필터는 동적 시스템의 상태를 예측·보정하며 결함 여부를 판단한다(Mohri et al., 2012). Table 6에서는 진동 응답에 따른 Kalman 필터에 대한 결함 검출 기준을 제시하였다.
결함 여부는 잔차(residual) 가 임계값 를 초과하는지 여부로 판정한다.
이때 잔차의 분포는 분포로 근사되며, 𝛼 = 0.05 기준에서 𝜏 = 3.84로 설정된다(Ghorbel et al., 2015).
Table 6.
Kalman Filter Fault detection criteria
| 𝛼 | Result | |
| 0.05 | 3.84 | Normal |
| 0.01 | 6.63 | Notice |
| 0.001 | 10.83 | Fault |
교량의 진동응답 데이터를 대상으로 칼만 필터(Kalman Filter)를 적용한 결함 검출 실험을 수행하였다. 대상 구조물은 주경간 400 m의 케이블 교량으로, 상판 및 주탑에 가속도계 24개, 변위계 8개, 온도센서 4개가 설치되어 있으며, 모든 센서는 CAN-BUS 기반 네트워크로 연결되어 있다. 계측 데이터는 100 Hz 주기로 수집되었으며, 시스템 상태방정식은 다음과 같이 정의되었다.
결함 검출은 예측값과 실제 계측값의 차이인 잔차(residual) 를 이용하였으며, 잔차의 제곱합이 χ2 분포 기반 임계값(유의수준 0.01, τ = 6.63)을 초과할 경우 결함으로 판정하였다(Farrar and Worden, 2012; Mohri et al., 2012). 노이즈 주입 실험을 통해 결함 검출 성능을 검증한 결과, 결함 검출률은 약 92.4%로 나타났으며, 데이터 손실이 5% 발생한 구간에서도 약 88.7%의 복원 정확도를 보였다. 실시간 처리속도는 약 4.8 ms/step으로 측정되어 실시간 SHMS 운용에 적합한 것으로 평가되었다.
이 결과는 Kalman Filter가 구조물의 물리적 모델을 기반으로 결함을 판별함으로써, 센서 노이즈와 통신 오류를 효과적으로 구분할 수 있음을 보여준다. 특히 고정밀 모델링이 가능한 교량 시스템에서는 높은 실시간성과 계산 효율성을 동시에 확보할 수 있다.
2.3.3 데이터기반 결함 검출(Data-driven Fault Detection)
데이터 기반 기법은 물리 모델 없이 데이터 패턴으로부터 결함을 탐지한다(Jin et al., 2015). Table 7에서는 주요 데이터 기반 결함 검출 기법에 대해 비교하였다.
(1) PCA(Principal Component Analysis)
정상 데이터를 학습, 새로운 데이터의 변동성()이 임계값을 초과할 경우 결함으로 판정한다(Feng et al., 2014).
(2) Autoencoder 기반 신경망
비지도 신경망 구조로 정상 데이터를 학습하여 복원오차()를 계산한다(Jin et al., 2015).
Autoencoder는 비선형 신호 및 복합 환경에서 높은 검출 성능을 보이며, 온도·진동이 복합적으로 작용하는 교량 계측 환경에 적합하다(Mohri et al., 2012; Feng et al., 2014).
(3) SVM(Support Vector Machine)
SVM은 결함 클래스와 정상 클래스를 분리하는 초평면을 학습하여 결함 여부를 분류한다(Chandola et al., 2009).
비선형 데이터의 경우 RBF 커널을 사용하며, 결함 검출 정확도가 90% 이상 보고되었다(Ghorbel et al., 2015).
Table 7.
Data-driven Fault detection methods comparison
2.3.4 하이브리드 결함 검출(Hybrid Fault Detection)
하이브리드 기법은 Kalman Filter의 물리적 모델과 Autoencoder의 비선형 학습모델을 결합하여, 정확도와 해석 가능성을 동시에 확보할 수 있고, 검출 기준은 Table 8과 같다(Mohri et al., 2012; Ghorbel et al., 2015).
Table 8.
Kalman Filter-Autoencoder Hybrid Fault detection criteria
| FI | Status | Action |
| 0.0–0.3 | Normal | - |
| 0.3–0.7 | Warning | Re-calculate |
| 0.7< | Fault | Alarm |
하이브리드 결함 검출 기법은 결함 탐지율이 높고, 통신결함(CAN-BUS), 센서 결함, 구조 응답 결함을 동시에 탐지할 수 있다(Feng et al., 2014).
전술한 결함 검출 알고리즘은 데이터의 특성과 시스템 모델의 정확도에 따라 적합한 방법이 적용되어야 최적의 결험 검출 및 복원이 가능하다. Table 9에 제시된 바와 같이 단기 결함 계측에는 통계적 기법 또는 Kalman 기법을, 장기 영구계측에는 Autoencoder 및 하이브리드 기법의 적용이 가장 효과적이다(Farrar and Worden 2012; Jin et al., 2015). 또한, CAN-BUS 기반 네트워크 환경에서는 FI(Fault Index)기반 자동 진단체계가 특히 유용하다(Mohri et al., 2012; Ghorbel et al., 2015).
Table 9.
Fault detection methods comparison
| Algorithms | Computing time (ms) | Accruacy | Robustness | Real-time | Difficulty | Reference |
| Hotelling | 3.2 | 78 | Medium | Good | Low | Chandola et al. (2009) |
| Kalman Filter | 4.8 | 86 | Good | Good | Normal | Farrar and Worden (2012) |
| Autoencoder | 12.5 | 91 | Excellent | Normal | High | Jin et al. (2015) |
| Hybrid (KF+AE) | 8.7 | 94 | Excellent | Good | High | Ghorbel et al. (2015) |
3. 결 론
본 연구를 통해 도출된 결론은 다음과 같다.
본 연구에서는 구조건전성 모니터링(Structural Health Monitoring, SHM) 시스템에서 수집되는 계측 데이터의 품질 저하 요인을 규명하고, 데이터 결함(Fault)의 유형, 검출 기법 및 알고리즘을 체계적으로 고찰하였다. SHMS 데이터는 센서 네트워크를 통해 실시간으로 획득되지만, 전원 불안정, 통신 오류, 센서 노후화, 온도·습도 등 외란 요인으로 인해 데이터 결함이 필연적으로 발생하여 구조 응답 해석 정확도를 저하시키고, 분석 알고리즘의 신뢰성 또한 저하된다.
데이터 결함은 크게 센서 결함(sensor fault), 신호 드리프트(signal drift), 데이터 손실(data loss), 노이즈 혼입(noise contamination)으로 구분되며, 검출 절차는 전처리–탐지–분류 및 복원의 단계로 구성된다. 데이터 결함은 단순한 계측 오차가 아닌, 구조물의 건전성 판단 과정 전반에 영향을 미치는 주요 요인으로 인식되어야 한다.
이러한 결함 검출을 위한 알고리즘을 통계적 기법, 모델기반 기법, 데이터기반 기법, 하이브리드 기법으로 구분하여 비교하였다. 통계적 기법(Hotelling’s T2, EWMA 등)은 구현이 간단하고 실시간성이 높으나, 비선형 데이터나 복합 환경에서는 검출 민감도가 낮다(Chandola et al., 2009). 모델기반 기법(Kalman Filter 등)은 시스템 행렬에 기반한 잔차 분석을 통해 결함을 판별할 수 있으며, 물리적 의미 해석에 용이하다(Farrar and Worden, 2012). 그러나 모델의 불확실성이 큰 복합 구조물에서는 오탐률이 증가할 수 있다. 데이터기반 기법(PCA, Autoencoder, SVM 등)은 학습 데이터의 통계적 특성과 복원오차를 이용하여 비선형 환경에서도 높은 검출 성능을 보였다(Jin et al., 2015; Feng et al., 2014). 특히 Autoencoder 기반 비지도 신경망은 복합계측 데이터의 이상 패턴을 효과적으로 탐지할 수 있어, 대규모 교량 모니터링 시스템의 자동화 진단에 적합함이 확인되었다. 마지막으로, 본 연구에서 제시한 하이브리드 결함 검출 기법(Kalman Filter + Autoencoder 융합)은 모델기반 예측성과 데이터기반 학습능력을 동시에 반영하여 높은 정확도(94%)와 실시간성을 확보하였다(Ghorbel et al., 2015). 또한 결함지수(Fault Index, FI)를 도입하여 결함의 정도를 정량화함으로써, 단순한 이상 탐지를 넘어 유지관리 의사결정에 활용가능한 수준으로 확장하였다.
