

1. 서 론
교량은 사회기반시설물로써 사람의 이동 및 물류 운송에 있어 매우 중요하다(Cho et al., 2007; Chai and Lee, 2012). 특히, 우리나라 국민들은 교량의 붕괴로 인한 인명피해 사고를 잊지 않고 있으며, 교량의 안전에 많은 관심을 가지고 있다. 국가에서도 교량을 안전하게 관리하기 위하여 「시설물의 안전 및 유지관리에 관한 특별법」(이하 ‘시설물안전법’이라 한다)(MOLIT, 2021a)을 제정하고, 이를 통해 시설물을 안전하게 사용할 수 있도록 주기적으로 유지관리를 수행하고 있다(Kyung et al., 2015). 교량은 형식, 최대 경간장, 연장 등에 따라 종별로 구분하고 있다. 교량의 종별에 따라 점검 및 진단 실시범위가 다르며 안전점검등 과업 내용에서도 차이가 있다. 특히, 교량의 안전성 평가는 제1종시설물 및 제2종시설물의 일부에 대해서 주로 수행되고 있다(Lee et al., 2016; Shin et al., 2018). 사용 하중에 대한 교량의 안전성을 평가하기 위해서는 「교량 내하력 평가 매뉴얼」(KALIS, 2006)의 내하력 평가를 수행한다. 내하력은 설계활하중에 내하율을 고려하여 산정하고, 이 때, 구조물의 손상, 결함, 재료적인 열화현상 등에 관한 실측자료를 반영하여 내하율을 보정한다. 여기서, 내하력은 구조물의 활하중에 대한 하중저항성능을 말하고, 내하율은 구조물의 극한저항성능에서 지속하중에 의한 하중영향을 뺀 값에 대하여 활하중에 의한 하중영향을 나눈 값을 말한다(MOLIT, 2014). 결국, 교량의 내하율을 확인함으로써, 교량이 외부 하중에 대해 안전하게 지지하고 있는지를 확인할 수 있다.
상대적으로 규모가 작은 소규모 교량에서는 안전성 평가가 의무화되어 있지 않은데, 이는 안전성 평가를 위해서는 많은 재원 및 기술자의 전문성이 요구되기 때문이다(Park and Yang, 2003; Jang et al., 2009; Lee et al., 2009). 제한된 예산으로 시설물을 효율적으로 관리하고 소규모 교량의 안전성을 확보하기 위해서는 소규모 교량의 안전성을 확인할 수 있는 체계가 필요하다.
따라서 본 연구에서는 교량의 제원, 형식, 공용년수, 상태평가 결과, 사용환경 등의 지표를 조사하여 안전성 평가에 의한 공용내하율과의 상관관계 분석을 수행하였으며, 분석 결과를 통해 공용내하율과의 상관성이 높은 지표를 도출하였다. 향후, 도출된 지표를 통해 다중회귀분석을 수행하여 교량 내하성능 추정 모델 개발을 수행하고자 하며 본 논문의 분석 결과를 기초자료로 활용하고자 한다.
2. 본 론
2.1 자료 수집 및 데이터셋 작성
교량 점검진단 보고서 상의 안전성 평가 부분의 지표별 데이터를 수집하기 위하여, 「도로 교량 및 터널 현황정보시스템」(MOLIT, 2022)의 자료를 참고하여 자료 수집 대상 교량을 선정하였다. 연구대상은 지방도 상의 교량으로써 상부구조 형식이 RC슬래브, 라멘, PSC I, 강상자인 교량으로 하였다. 서울, 경기 등 전국 지자체 협조를 통해, 「시설물통합정보관리시스템」(MOLIT, 2021b)에 저장된 점검진단 보고서를 수집하였다. 전체 약 2,161건의 점검진단 보고서를 수집하였으며, 데이터 용량으로는 약 530 GB 정도였다.
점검진단 보고서는 장별로 형식 및 구성이 정형화되어 있어서, 본 연구에서 필요로 하는 안전성 평가 관련 부분만 확인하여 지표별 값들을 추출하였다. 교량별 보고서에 수록된 지표별 값들을 추출하여 데이터셋으로 만들기 위해서, 문서 파싱(Parsing) 알고리즘을 사용하였다. 관리주체 및 교량 형식, 교량명 등을 구분하여 전체 보고서 파일을 선별 및 정리하였다. 각 보고서에서 추출하고자 하는 데이터 항목은 교량의 관리 정보, 제원 정보, 설계 정보, 상태평가 결과, 재료시험 결과, 안전성 평가 결과로 구분된 약 60개 항목이다. 최종적으로 총 260건의 데이터셋을 작성하였다. Table 1은 교량 형식별로 나타낸 데이터셋의 수를 나타낸다.
Table 1.
Composition of data sets for each bridge
| Bridge type | Number of data sets | Ratio (%) |
| PSC I | 57 | 21.9 |
| RA | 34 | 13.1 |
| RCS | 89 | 34.2 |
| STB | 80 | 30.8 |
| Total | 260 | 100.0 |
데이터셋의 지역별, 준공년도별, 설계하중별, 연장별, 최대경간장별 통계는 Table 2부터 Table 6까지 나타낸 것과 같다. 지역별로는 경상남도 지역 교량이 104개소로 전체 데이터의 약 40% 수준을 차지하고, 준공년도별로는 1981년부터 2000년 사이에 준공된 교량이 178개소로 두 기간 사이에 준공된 교량 수가 전체의 68.5%를 차지한다. 설계하중에 따라서는 1등교인 DB-24가 164개소로 전체 데이터의 63.1%를 차지하고, 교량의 총 연장에 따라 분류하면 100 m 이상의 교량이 125개소로 48.1%를 차지하고 있다. 또한, 최대경간장은 10 m 이상~20 m 미만인 교량이 105개소로 40.4%로 가장 많이 차지하고 있다.
Table 2.
Composition of data sets by region
Table 3.
Composition of data sets by built year
| Range of built year | Number of data sets | Ratio (%) |
| 2001~2010 | 44 | 16.9 |
| 1991~2000 | 115 | 44.2 |
| 1981~1990 | 63 | 24.2 |
| 1971~1980 | 27 | 10.4 |
| ~1970 | 11 | 4.2 |
| Total | 260 | 100.0 |
Table 4.
Composition of data sets by design load
| Design load | Number of data sets | Ratio (%) |
| DB-13.5 | 11 | 4.2 |
| DB-18 | 83 | 31.9 |
| DB-24 | 164 | 63.1 |
| Not checked | 2 | 0.8 |
| Total | 260 | 100.0 |
Table 5.
Composition of data sets by total length
| Range of total length (m) | Number of data sets | Ratio (%) |
| 100~ | 125 | 48.1 |
| 50~99 | 47 | 18.1 |
| 40~49 | 17 | 6.5 |
| 30~39 | 23 | 8.8 |
| 20~29 | 20 | 7.7 |
| ~19 | 28 | 10.8 |
| Total | 260 | 100.0 |
Table 6.
Composition of data sets by maximum span length
| Range of maximum span length (m) | Number of data sets | Ratio (%) |
| 50~ | 84 | 32.3 |
| 40~49 | 1 | 0.4 |
| 30~39 | 28 | 10.8 |
| 20~29 | 19 | 7.3 |
| 10~19 | 105 | 40.4 |
| ~9 | 23 | 8.8 |
| Total | 260 | 100.0 |
2.2 데이터 코딩 및 크리닝
안전성 평가자료로부터 작성한 데이터셋의 분석을 위해 데이터 전처리 후 통계분석, 회귀분석 알고리즘 적용까지 다양한 작업이 필요하므로 Python을 활용하였다. Python은 직관적인 프로그래밍 언어로 코딩이 익숙하지 않은 사람도 학습 및 활용이 용이하며, 다양한 분석도구(라이브러리, 프레임워크 등)를 지원하기 때문에 많은 양의 데이터를 신속하고 정확하게 분석할 수 있는 장점이 있다. 해당 프로그램에서 처리 가능하도록 설계하중, 상태평가 결과와 같은 범주형 데이터는 수치형 데이터로 변환하였고, 응답비, 응답보정계수, 공용내하율, 공용내하력과 같이 재하시험 결과와 상호관계식에 의해 계산이 가능한 데이터는 계산을 통해 데이터화 하였다.
Table 7은 설계하중, 상태평가 결과, 탄산화 깊이 시험 결과, 염화물 함유량 시험 결과를 수치형 데이터로 변환한 것을 나타낸다.
Table 7.
Transformation results of quantitative data
| Label | Design loads | Condition evaluation results |
Test results (carbonation depth) |
Test results (chloride content) |
| 1 | DB-13.5 | e | e | e |
| 2 | DB-18 | d | d | d |
| 3 | DB-24 | c | c | c |
| 4 | - | b | b | b |
| 5 | - | a | a | a |
박스그래프를 통해 전체적인 데이터의 집합 범위 및 중앙값, 이상치(Outlier)를 확인했으며, 사분위수(IQR) 범위를 활용한 최솟값 및 최댓값을 벗어나는 데이터를 확인하였다. 지표별 데이터 분포를 확인하기 위해 데이터 항목별 히스토그램을 작성하여 검토하였다. 또한, 공용내하율과 각 지표 사이의 관계를 파악하고자 산점도를 작성하여 검토하였다.
데이터 크리닝이란 정확한 분석을 위해 데이터를 검토하는 과정을 말하며, 수집한 데이터에 존재하는 결측값이나 오류를 수정, 보완하는 절차가 포함된다. 향후, 데이터의 상관분석 및 회귀분석을 위해 적합한 형식으로 데이터셋을 정제하여 사용하고자 데이터 크리닝을 수행하였다. 제원 및 설계정보의 경우, 동일 교량은 다른 연도 정기점검 데이터를 활용하여 결측값을 보정하고, 열화환경과 교통량은 기준정보에 따라 업데이트하였다. 또한, 결측값이 높은 데이터 항목과 처짐, 고유진동수, 충격계수, 응답비, 기본내하율과 같이, 공용내하율 계산식에 포함된 데이터 항목은 분석을 위한 데이터셋으로 적합하지 않아 제외하였다. 최종적으로 교량의 형식별 데이터 정제 후, 상관분석에 사용하는 데이터셋은 168개이며, 교량 형식별로는 PSC I 33개, RA 21개, RCS 57개, STB 57개 이다. Table 8은 상관분석에 사용할 최종 데이터셋 구성을 나타낸 것이다.
Table 8.
Composition of data sets
| Bridge type | Number of data sets | Ratio of utilization (%) | |
| Before cleaning | After cleaning | ||
| PSC I | 57 | 33 | 57.9 |
| RA | 34 | 21 | 61.8 |
| RCS | 89 | 57 | 64.0 |
| STB | 80 | 57 | 71.3 |
| Total | 260 | 168 | 64.6 |
정규성 검정은 정규분포를 따르는 모집단에서 표본들이 취해졌는지 검정하는 것이다. 본 연구에서는 전체 표본 수가 30 이상인 독립변수는 정규분포를 이룬다는 중심극한정리 이론에 따라 별도의 정규성 검정은 필요 없을 것으로 판단된다. 다만, 교량 횡단은 표본 수가 30 이상이지만 집단의 구분이 2개 이하로 구성되어 본 연구에서는 제외하였다. 상기 세 가지 단계에서 제외된 변수 외에도 질적 척도로 이루어진 상 ‧ 하부 형식, 노선 구분은 서열이 존재하지 않는 단순 명목척도로 선형 분석에 적합하지 않은 변수라 판단되어 본 연구에서 제외하였다.
2.3 상관 분석 및 결과
상관분석이란 서로 대등한 두 변수(X, Y) 간의 직선적 관련성의 정도를 상관계수로 표현하고, 그 통계적 유의성 여부를 검정하는 방법을 말한다. 상관계수를 구하는 방법은 분석하는 데이터의 분포와 양에 따라 적합한 검정 방식을 사용해야 하고, 가장 많이 사용되는 방식은 Pearson 상관계수를 통한 분석이다. Pearson 상관계수는 상관계수의 유의성을 검증하기 위해 두 변수가 정규분포를 이룬다는 가정이 필요하고, 직선적인 관련성만 알 수 있는 척도이다.
본 연구에서는 사용 가능한 데이터셋이 적고 정규분포를 이룬다고 가정하기 어렵다. 또한 그래프로 확인했을 때, 공용내하율과 선형적 상관관계가 예상되지 않는 지표도 있었다. 다만, 사용 가능한 데이터의 현실적 어려움을 반영하여 Pearson 상관분석을 실시하였다. 상관계수가 취할 수 있는 값의 범위는 -1에서 +1 사이가 된다. 상관관계가 없을 때, 그 값이 0이 되며, 완전한 상관관계를 이루면 -1 또는 +1이 된다. 보통 상관계수의 절대값이 0.8 이상이면 강한 상관관계, 0.8에서 0.4사이 이면 중간정도의 상관관계, 0.4 이하이면 약한 상관관계를 가진다고 할 수 있다. 다만, 본 연구에서는 활용하는 데이터에 제약이 있고, 전체 지표별 상관계수 비교 시, 0.4 이상의 결과값을 가지는 지표가 많지 않아 기준을 다소 조정하였다.
총 17~20개 지표를 사용하여 Pearson 상관계수를 구하기 때문에 사용하는 변수가 많으므로 결과를 효율적으로 시각화하기 위해 표 대신에 히트맵(Heatmap)을 활용하였다. 히트맵은 데이터 세트에서 변수 간의 짝(Pair)을 지어 상관관계를 시각화하는 그래프로, 그래프에서 각 셀은 두 변수 간의 상관계수를 나타내며 셀의 색상은 상관관계의 강도와 방향을 나타낸다. 붉은색은 양의 상관관계를 나타내고, 푸른색은 음의 상관관계를 나타낸다. 색상의 강도는 상관관계의 강도를 나타내며 짙어질수록 상관계수가 높다고 볼 수 있다.
Fig. 1은 교량 형식별 공용내하율과의 상관계수 히트맵을 나타낸 것이다. PSC I의 상관계수가 |0.3| 이상인 항목은 ‘상태평가(바닥판)’, ‘상태평가(포장)’, ‘동결융해 노출등급’, ‘염화물침투량’이고, RA의 상관계수가 |0.3| 이상인 항목은 ‘최대경간장’, ‘동결융해 노출등급’, ‘비래염분 노출등급’, ‘탄산화 깊이’ 이다. 또한, RCS의 상관계수가 |0.3| 이상인 항목은 없었으며, 상대적으로 상관계수가 높은 항목으로 ‘차선수’, ‘동결융해 노출등급’, ‘제설제 노출등급’, ‘비래염분 노출등급’, ‘탄산화 깊이’, ‘염화물침투량’ 이다. STB의 상관계수가 |0.3| 이상인 항목은 ‘염화물침투량’ 이다.
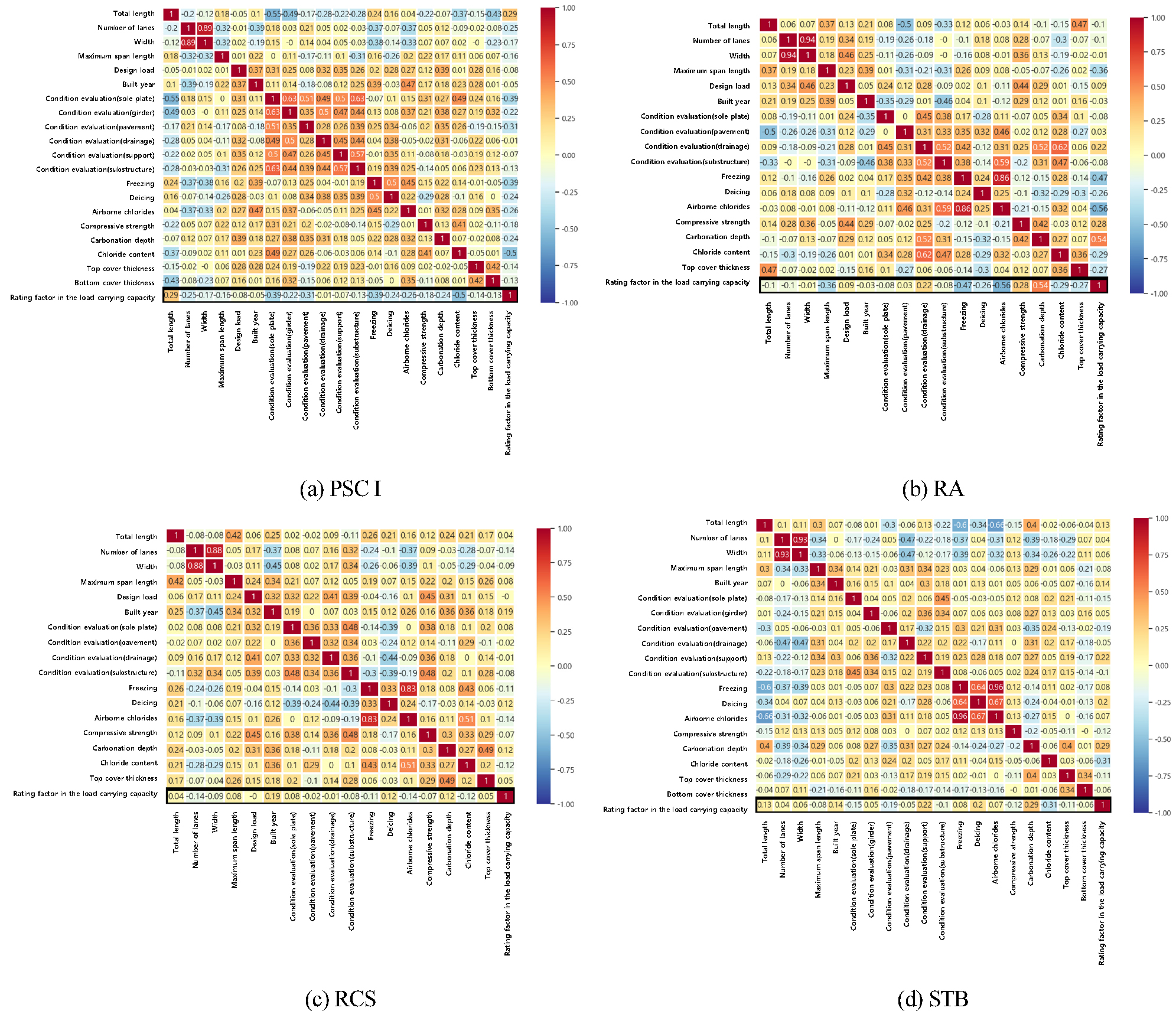
상관계수가 검토수준(0.2 또는 0.3) 이상인 경우, 해당 속성의 유의확률(p-value)을 검토하였다. 이는 유의성 검정을 위한 것으로, ‘상관관계가 없다’ 즉, ‘상관계수의 값이 0 이다’라는 귀무가설을 검정하는 것이다. 귀무가설이 옳다고 가정했을 때, 통계치가 관측될 확률을 유의확률라고 하며, 이를 기준이 되는 유의수준(Significance level)과 비교하여 더 작은 경우 귀무가설을 기각하고 ‘유의한 상관관계가 있다’라는 결론을 얻을 수 있다. 본 연구에서는 일반적으로 사용하는 95% 신뢰도 기준으로 유의수준=0.05를 사용하여 검증하였다. 상관계수가 검토수준 이상일 때, 함께 검토한 유의확률이 유의수준인 0.05 이하인 경우의 항목을 교량별로 도출하였다.
PSC I의 경우, ‘상태평가(바닥판)’, ‘동결융해 노출등급’, ‘염화물침투량’이고, RA의 경우, ‘동결융해 노출등급’, ‘비래염분 노출등급’, ‘탄산화깊이’ 이다. 또한, RCS의 경우, ‘상태평가(하부)’, ‘압축강도’이고, STB의 경우, ‘염화물침투량’, ‘탄산화깊이’이다.
3. 결 론
본 연구에서는 소규모 교량의 안전성을 비교적 쉽게 추정할 수 있는 모델 개발을 위해, 교량의 점검진단 보고서 상의 지표별 값을 데이터화하고 공용내하율과의 상관관계 분석을 수행하였다. 연구 대상 교량으로 상부구조형식 4가지(PSC I, RA, RCS, STB)를 고려하였으며, 교량 유형별 공용내하율과 상관관계를 가지는 지표들을 각각 도출하였다. 향후, 도출된 지표에 대해 다중회귀분석을 수행하여 교량의 내하성능을 추정할 수 있는 모델을 개발하고자 하며, 모델을 통해 도출된 값을 점검진단 보고서 상의 내하력과 비교하여 판별 정확도를 검토하고자 한다.
전국 지자체 협조를 통해 많은 수의 점검진단 보고서를 수집하였지만, 필요한 데이터를 추출하고 데이터 클리닝 이후, 실제 분석에 활용한 데이터의 수는 제한적이었다. 향후에는 인공지능을 활용한 데이터 증강을 수행하여 보다 많은 데이터를 확보하고자 하며, 지표별 특성을 반영하여 비선형성을 반영하고자 한다.
