

1. 서 론
2. 본 론
2.1 지표선정 및 사용 데이터 통계
2.2 데이터 코딩 및 데이터 크리닝
2.3 변수 통계량 및 히스토그램
2.4 상관관계 분석
2.5 상관관계 분석 결과
3. 결 론
1. 서 론
교량은 하천이나 도로 등의 공간 위로 사람이나 차량이 건널 수 있도록 만든 시설물로써 하천, 섬, 그리고 산이 많은 우리나라 지형적 특성 및 물류 운송과 같은 현대사회의 특성을 고려할 때, 매우 중요한 사회기반시설물이다(Cho et al., 2007; Chai and Lee, 2012). 우리나라는 안전하게 교량을 사용하기 위하여 「시설물의 안전 및 유지관리에 관한 특별법」(이하 ‘시설물안전법’이라 한다)(MOLIT, 2021a)에 의해 주기적으로 유지관리를 수행하고 있다(Kyung et al., 2015; Lee et al., 2021). 교량의 경우, 교량의 형식, 최대 경간장, 연장 등에 따라 제1종시설물, 제2종시설물, 제3종시설물로 구분하고 있으며, 제3종시설물에도 속하지 않는 상대적으로 규모가 작은 교량은 기타(종외)시설물로 구분하고 있다. 교량의 종별에 따라 점검 및 진단 실시범위가 다르며 안전점검등 과업 내용에서도 차이가 있다. 특히, 교량의 안전성 평가는 제1종시설물 및 제2종시설물의 일부에 대해서 주로 수행되고 있다(Lee et al., 2016; Shin et al., 2018).
현행의 교량 안전성 평가를 수행하기 위해서는 설계자료를 포함한 유지관리 자료 등의 검토, 교량 외관상태 조사, 비파괴조사 및 재료시험 등이 요구되며 특히, 차량재하시험을 통한 교량 거동의 계측과 유한요소해석을 이용한 교량 거동의 해석과 같이 많은 재원 및 기술자의 전문성이 요구된다(Park and Yang, 2003; Lee et al., 2009; Jang et al., 2009). 따라서 우리나라 도로교량 약 37,000개소(MOLIT, 2022; Park et al., 2020)에 대해 안전성 평가를 수행하는 것은 현실적으로 어려우며 효율적이지도 않다. 현행의 시설물안전법 상에서는 정기점검 수행을 통해, 교량 상태에 따라 상위의 안전점검등 과업을 수행할 수 있으며, 정밀안전점검 수행 시, 필요에 따라 안전성 평가를 수행할 수 있도록 되어 있다. 하지만 정기점검 결과만으로 안전성 평가 수행 여부를 결정하기 어렵고 안전성 평가 수행의 결정을 위해서는 상위의 안전점검등 단계를 수행해야 하므로 전체 도로교량 중 대부분을 차지하는 중․소규모 교량의 안전성 평가는 수행되지 못하고 있는 실정이다.
따라서 안전성 평가를 수행하지 않는 제3종 및 기타 교량에 대해서 내하성능을 추정하고 추정 결과를 바탕으로 안전성 평가가 요구되는 교량을 선별할 수 있는 연구가 필요하다. 해당 연구 결과를 통해 교량 관리주체에게 안전성 평가 수행 여부의 의사결정을 위한 정보를 제공함으로써 중․소 규모의 교량 안전에 기여할 수 있을 것으로 생각된다. 이를 위해, 본 논문에서는 교량의 제원, 형식, 공용년수, 상태평가 결과, 사용환경 등의 지표를 조사하여 안전성 평가에 의한 공용내하력과의 상관관계 분석을 수행하였으며, 분석 결과를 통해 공용내하력과 상관성 높은 지표를 도출하였다. 향후, 도출된 지표를 통해 다중회귀분석을 수행하여 교량 내하성능 추정 모델 개발을 수행하고자 하며 본 논문의 분석 결과를 기초자료로 활용하고자 한다.
2. 본 론
2.1 지표선정 및 사용 데이터 통계
지표별 내하성능 상관관계 분석을 위해 시설물안전법에 따른 안전성 평가 보고서를 수집하고, 데이터를 정리하였다. 자료수집 대상 교량은 상부구조 형식이 RC(Reinforced Concrete) 슬래브교, RC 라멘교이며, 안전성 평가 보고서에 기술되지 않았거나 미흡한 데이터는 「도로 교량 및 터널 현황정보시스템」(MOLIT, 2022)과 「시설물통합정보관리시스템」(MOLIT, 2021b)자료를 참고하여 가능한 모든 데이터를 수집하였다.
안전성 평가 보고서 등 각종 자료를 통해 수집된 데이터 항목은 준공년도, 설계하중, 상․하부 형식, 연장, 최대경간장, 폭, 차선수, 횡단구분, 노선구분, 일교통량, 상태평가 결과, 압축강도, 탄산화 깊이 시험결과, 염화물 함유량 시험결과, 상․하부 피복두께 측정결과, 실측․이론 처짐량, 처짐비, 실측․이론 고유진동수, 실측․이론 충격계수, 응답비, 응답보정계수, 기본내하율, 공용내하율, 공용내하력이며, 수집된 데이터 중 상태평가 결과, 탄산화 깊이 시험결과, 염화물 함유량 시험결과, 상․하부 피복두께 측정결과는 실시 부재에 따라 데이터 결과가 변하므로 지표 선정 시, 최소등급 또는 최솟값을 선정하였다. 응답비, 응답보정계수, 공용내하율, 공용내하력과 같이 재하시험 결과와 상호관계식에 의해 계산이 가능한 데이터는 계산을 통해 데이터화 하였고, 내하력 데이터가 없거나 추론이 불가능한 교량의 데이터는 본 연구에서 제외하였다.
수집한 자료로부터 지표별로 데이터화 하여 데이터 크리닝을 거쳐 상관관계 분석에 사용한 데이터의 통계는 다음과 같다. Table 1은 본 연구에 사용된 교량 98개소의 표본 데이터 중, 지역별 위치를 나타낸 것이다. 경상남도 지역 교량이 74개소로써 전체 표본 수의 약 75%이다. Table 2는 교량의 준공년도를 기준으로 분류한 것이다. 1981년부터 2000년 사이에 준공된 교량이 74개소로써 두 기간에 걸쳐 준공된 교량의 수가 전체 표본 수의 약 75%를 차지하고 있다. Table 3은 교량의 설계하중에 따라 분류한 것으로써 1등교인 DB-24가 전체 표본의 약 55%를 차지하고 있다. Table 4는 교량의 상부구조 형식에 따른 분류로써 RC 슬래브와 RC 라멘이 2:1의 비율을 이루고 있다.
Table 1.
Statistics of collected data by region
| Region | Number of collected data |
| Daejeon | 12 |
| Sejong | 3 |
| Chungbuk | 2 |
| Chungnam | 7 |
| Gyeongnam | 74 |
| Total | 98 |
Table 2.
Statistics of collected data by built year
| Range of built year | Number of collected data |
| 2001 ~ 2010 | 9 |
| 1991 ~ 2000 | 45 |
| 1981 ~ 1990 | 29 |
| 1971 ~ 1980 | 9 |
| ~ 1970 | 6 |
| Total | 98 |
Table 3.
Statistics of collected data by design load
| Design load | Number of collected data |
| DB-13.5 | 6 |
| DB-18 | 37 |
| DB-24 | 54 |
| Not checked | 1 |
| Total | 98 |
Table 4.
Statistics of collected data by superstructure type
| Superstructure type | Number of collected data |
| RC-Slab | 67 |
| RC-Rahmen | 31 |
| Total | 98 |
Table 5는 교량의 총 연장에 따라 분류한 것으로 50 m에서 99 m 사이의 교량과 19 m 이하 교량이 각각 약 25% 정도로 분포하고 있다. Table 6은 최대 경간장에 따른 분류로써 10 m에서 19 m 사이의 최대 경간장을 가지는 교량이 74개소로 가장 많이 분포하고 있다. Table 7은 도로등급에 따른 분류로써 일반국도 상의 교량 28개소, 지방도 상의 교량 35개소이고, 이는 전체 표본의 약 64%를 차지하고 있다. 본 연구에 사용된 데이터의 표본은 경상남도 지역의 공용연수 30년 이상, 최대 경간장 20 m 이내의 1등교(DB-24)교량으로 표현할 수 있다.
Table 5.
Statistics of collected data by total length
| Range of total length (m) | Number of collected data |
| 100 ~ | 6 |
| 50 ~ 99 | 24 |
| 40 ~ 49 | 12 |
| 30 ~ 39 | 18 |
| 20 ~ 29 | 12 |
| ~ 19 | 26 |
| Total | 98 |
Table 6.
Statistics of collected data by maximum span length
| Range of maximum span length (m) | Number of collected data |
| 50 ~ | 6 |
| 40 ~ 49 | - |
| 30 ~ 39 | 2 |
| 20 ~ 29 | 1 |
| 10 ~ 19 | 74 |
| ~ 9 | 15 |
| Total | 98 |
Table 7.
Statistics of collected data by road class
2.2 데이터 코딩 및 데이터 크리닝
안전성 평가자료로부터 수집된 지표는 많은 양의 정보와 데이터를 포함하고 있다. 따라서 이런 정보와 데이터를 신속하고 정확하게 분석하며, 사용 및 데이터 관리가 편리한 IBM SPSS 프로그램을 활용하여 분석을 수행하였다. SPSS 프로그램은 전문 사용자가 아니더라도 일반 사용자가 데이터를 입력하고 데이터에 관리에 어려움이 없으며, 통계분석을 목적으로 IBM에서 개발한 소프트웨어이다.
수집된 데이터는 SPSS 데이터로 코딩하여 변수로 생성하였으며, 설계하중, 상태평가 결과 및 탄산화 깊이 시험 및 염화물 함유량 시험 결과와 같은 서열척도는 Table 8에 나타낸 것과 같이, 양적 척도로 변환하여 분석을 수행하였다.
Table 8.
Transformation results of quantitative data
| Label | Design loads | Condition evaluation results |
Test results (carbonation depth) |
Test results (chloride content) |
| 1 | DB-24 | a | a | a |
| 2 | DB-18 | b | b | b |
| 3 | DB-13.5 | c | c | c |
| 4 | - | d | d | d |
| 5 | - | e | e | e |
데이터 크리닝이란 정확한 분석을 위해 데이터를 검토하는 과정을 말하며 대표적으로 결측값(Missing value) 처리, 이상치(Outlier) 처리, 정규성 검정(Normality test)의 총 세 가지 단계로 구분된다. 먼저 결측값 처리는 분석에 필요없는 데이터를 제외시키는 작업으로 SPSS 프로그램에서 ‘시스템 결측값 처리’를 할 수 있도록 필요없는 데이터는 공란으로 처리하였다. 이상치 처리는 데이터 범위를 크게 벗어난 이상치로 인해 평균을 극단적으로 만드는 값을 제거하는 것으로 ‘데이터 탐색’ 기능을 이용하여 극단적인 이상치를 제거해 나가는 방식으로 수행하였다. Fig. 1은 이상치 제거를 위한 데이터 처리 결과를 나타낸 것으로써 별표와 숫자는 극단적인 이상치와 변수의 행번호를 나타낸다.
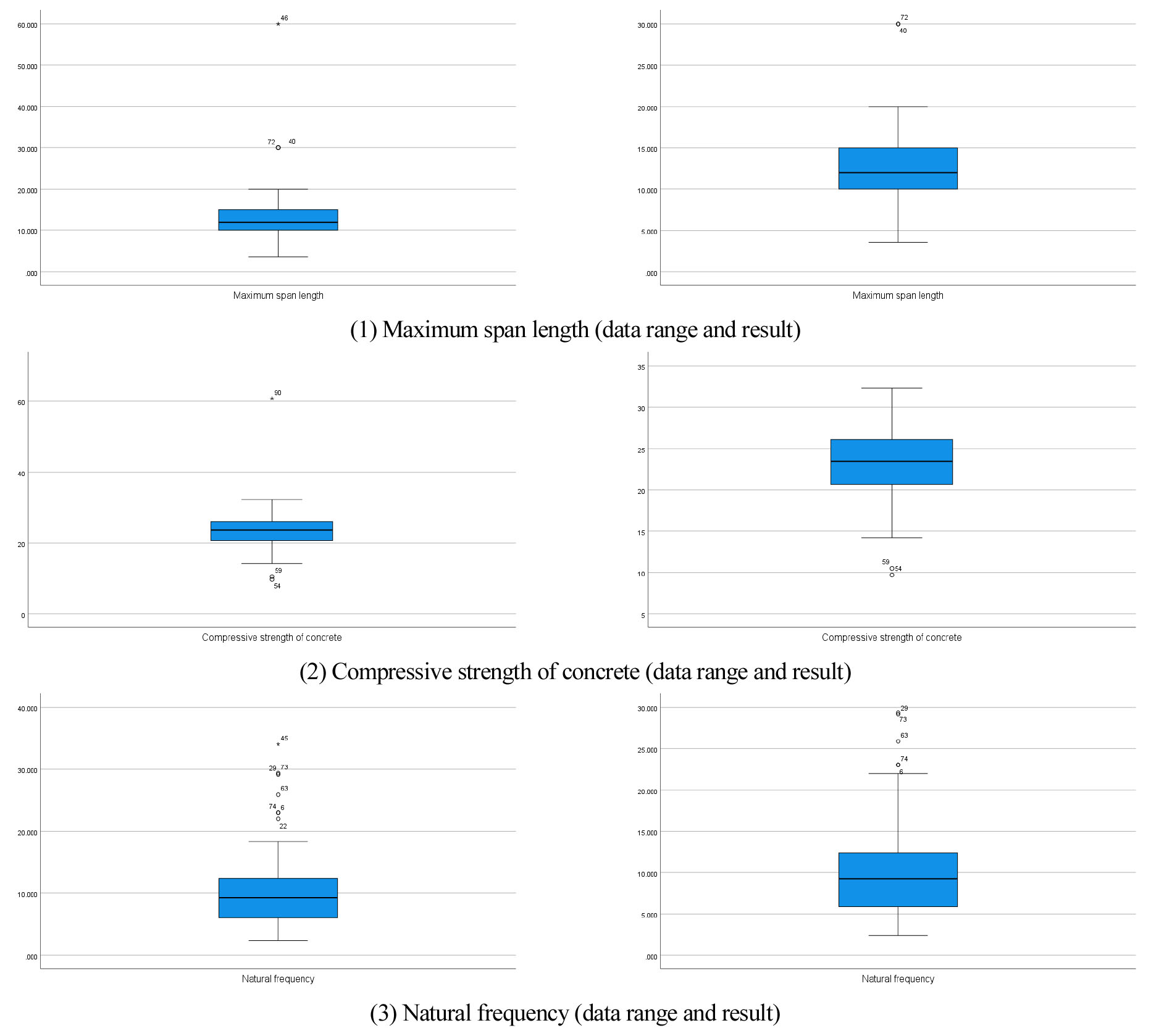
정규성 검정은 정규분포를 따르는 모집단에서 표본들이 취해졌는지 검정하는 것이다. 본 연구에서는 전체 표본 수가 30 이상인 독립변수는 정규분포를 이룬다는 중심극한정리 이론에 따라 별도의 정규성 검정은 필요 없을 것으로 판단된다. 다만, 교량 횡단은 표본 수가 30 이상이지만 집단의 구분이 2개 이하로 구성되어 본 연구에서는 제외하였다. 상기 세 가지 단계에서 제외된 변수 외에도 질적 척도로 이루어진 상․하부 형식, 노선 구분은 서열이 존재하지 않는 단순 명목척도로 선형 분석에 적합하지 않은 변수라 판단되어 본 연구에서 제외하였다.
2.3 변수 통계량 및 히스토그램
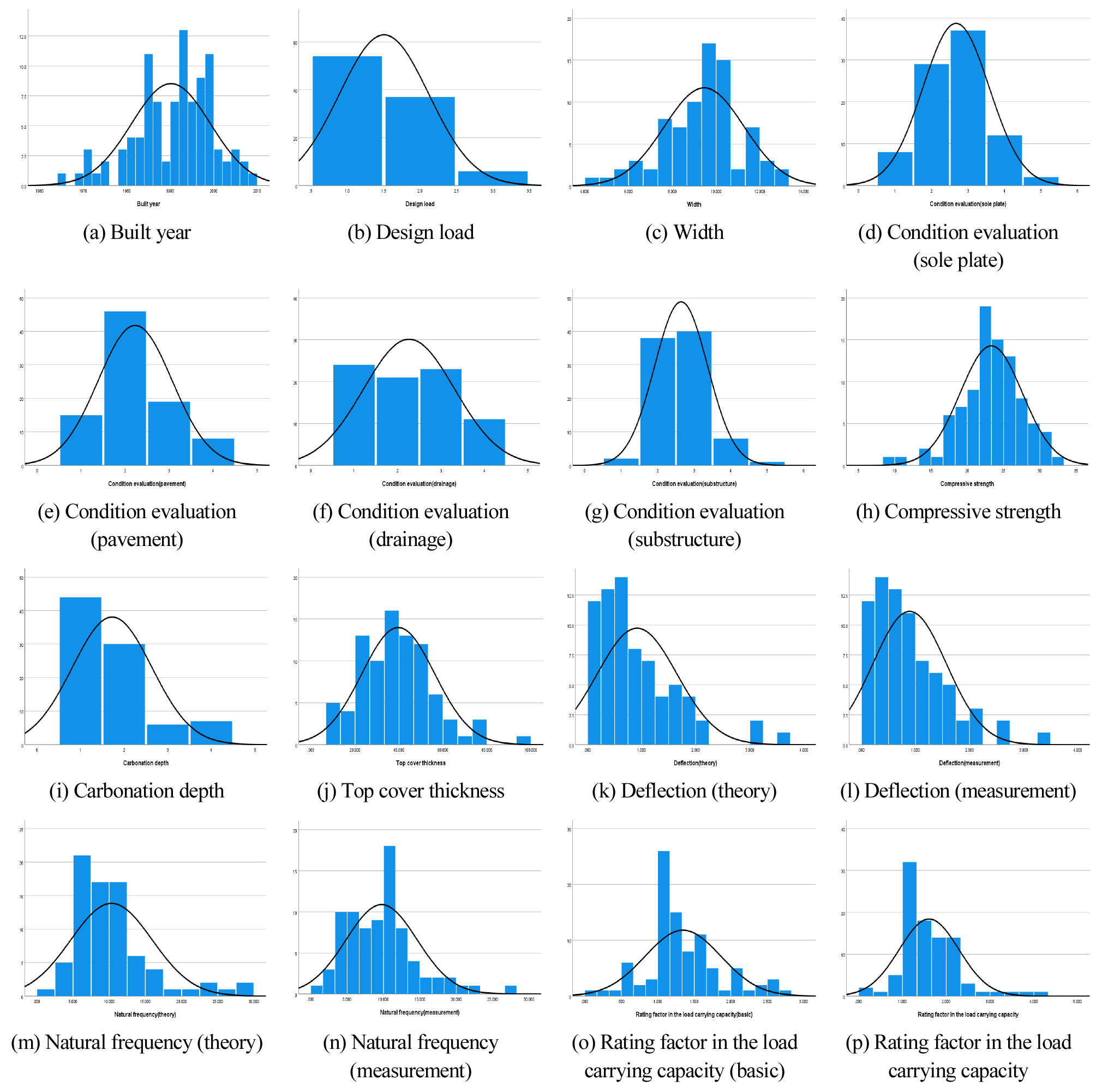
데이터 크리닝을 실시하여 확정된 변수들의 통계량과 히스토그램은 각각 Table 9와 Fig. 2에 나타낸 것과 같다.
Table 9.
Variable statistics
2.4 상관관계 분석
변수와 변수 간의 관계, 둘 또는 그 이상의 변수들에서 한 변수가 변함에 따라 다른 변수가 어떻게 변하는 것과 같은 변화의 연관성 정도, 변화의 크기 정도와 방향을 상관관계(Correlation)라고 한다. 따라서, 상관관계 분석(Correlation analysis)은 독립변수를 변화시켰을 때, 종속변수의 변화 정도를 분석하는 것을 말한다. 상관관계 분석은 모든 통계분석의 기본이 되며, 변수 간에 관련성이 없으면 다른 분석에서도 의미있는 통계분석 결과를 얻을 수 없다.
상관관계는 공분산 혹은 공변량(한 변수의 분산 (또는 변량)중에서 다른 변수와 같이 변화하는 분산)의 정도에 따라 결정된다고 볼 수 있다. 여기서 공변량(Covariance)은 두 변수의 값이 각각의 평균으로부터 떨어져 있는 정도를 나타내는 특성값으로 편차의 곱을 평균하여 구하며, 변화하는 공변량이 클수록 직선에 가깝고 그러면 상관관계는 높아진다.
상관계수는 이러한 변수 간 상관관계의 정도를 수치로 표시하는 지수로써, -1에서 1 사이의 값으로 나타낸다. 이때, 0에 가까울수록 상관관계는 낮아지며, 절대값 1에 가까울수록 상관관계는 높아진다. 상관계수 값에 의한 결정은 대체로 Table 10과 같은 영역을 선택하여 관계정도를 파악하는데 낮은 상관계수 일지라도 버려서는 안되며, 해석 및 조사 결과의 가치에 따라 상관관계를 파악해야 한다.
본 연구에서는 상관계수는 두 변수 간의 관련성을 구하기 위해 보편적으로 이용되는 Pearson 상관계수(Pearson correlation coefficient, r=X와 Y가 함께 변하는 정도 / X와 Y가 각각 변하는 정도)를 이용하여 분석을 수행하였다.
Table 10.
Correlation degree according to correlation coefficient
| Correlation coefficient | Degree of correlation | Correlation coefficient | Degree of correlation |
| ± 0.8 ~ | Very high | ± 0.2 ~ 0.4 | Low |
| ± 0.6 ~ 0.8 | High | ± 0 ~ 0.2 | Few |
| ± 0.4 ~ 0.6 | A little high | 0 | None |
변수 관계의 방향은 양(+)과 음(-)으로 표현하며, 관계의 방향에 따라 한쪽이 증가할 때 다른 쪽도 증가하는 관계, 즉 증감의 방향이 같은 경우, 양(+)의 상관관계가 있으며, 한쪽이 감소할 때, 다른 쪽이 증가하는 관계, 즉 증감의 방향이 반대인 경우, 음(-)의 상관관계가 있는 것으로 본다. 상관관계는 인과관계가 아닐 수도 있다는 점에 유의해야 한다. 즉, 독립변수와 종속변수의 관계일 수도 있고 아닐 수도 있다. 또한, 관계의 정도는 확률적 표현인 만큼 상관계수는 두 변수 관계의 상관성에 대한 예측의 정확도를 나타내는 것이다.
2.5 상관관계 분석 결과
공용내하력과 독립변수 간의 상대적 영향력을 파악하기 위해 Pearson 상관분석을 실시하여 상관관계를 조사하였다. 상관분석의 귀무가설을 ‘공용내하력과 독립변수 간에 상관관계가 없다’이고, 대립가설은 ‘공용내하력과 독립변수 간에 상관관계가 있다’로 정의되며, 유의확률 분석 결과 준공년도, 설계하중, 폭, 상태평가 바닥판, 상태평가 포장, 상태평가 배수, 상태평가 하부, 압축강도, 탄산화 깊이 시험결과, 상부 피복두께 측정결과, 실측․이론 처짐량, 실측․이론 고유진동수, 기본내하율, 공용내하율의 유의확률이 유의수준 0.05 이하로 나타나 대립가설이 채택되었다.
유의수준을 만족하는 변수 중 설계하중, 상태평가 배수, 압축강도, 탄산화 깊이 시험결과, 이론 처짐량, 기본내하율, 공용내하율은 상관계수가 ±0.4 이상으로 상관관계를 나타내는 것으로 분석되었다.
두 변수가 서로 어떤 유형으로 어느 정도의 관계를 갖고 있는지 변수의 관찰값을 XY-평면에 좌표로 나타낸 것을 산점도(Scatter diagram)라 하며, 상관계수가 ±0.2 이상 변수의 산점도는 Fig. 3에 나타낸 것과 같다. Fig. 3에서 확인할 수 있듯이 공용내하력은 준공년도가 오래될수록, 교량 폭과 압축강도, 이론․실측 고유진동수, 기본내하율, 공용내하율이 클수록, 상부 피복이 깊을수록 커지며, 설계하중이 작을수록, 상태평가 바닥판․포장․배수․하부, 탄산화 깊이 시험결과가 ‘a’ 등급일수록, 이론․실측 처짐량이 작을수록 커지는 상관관계가 도출되었다.
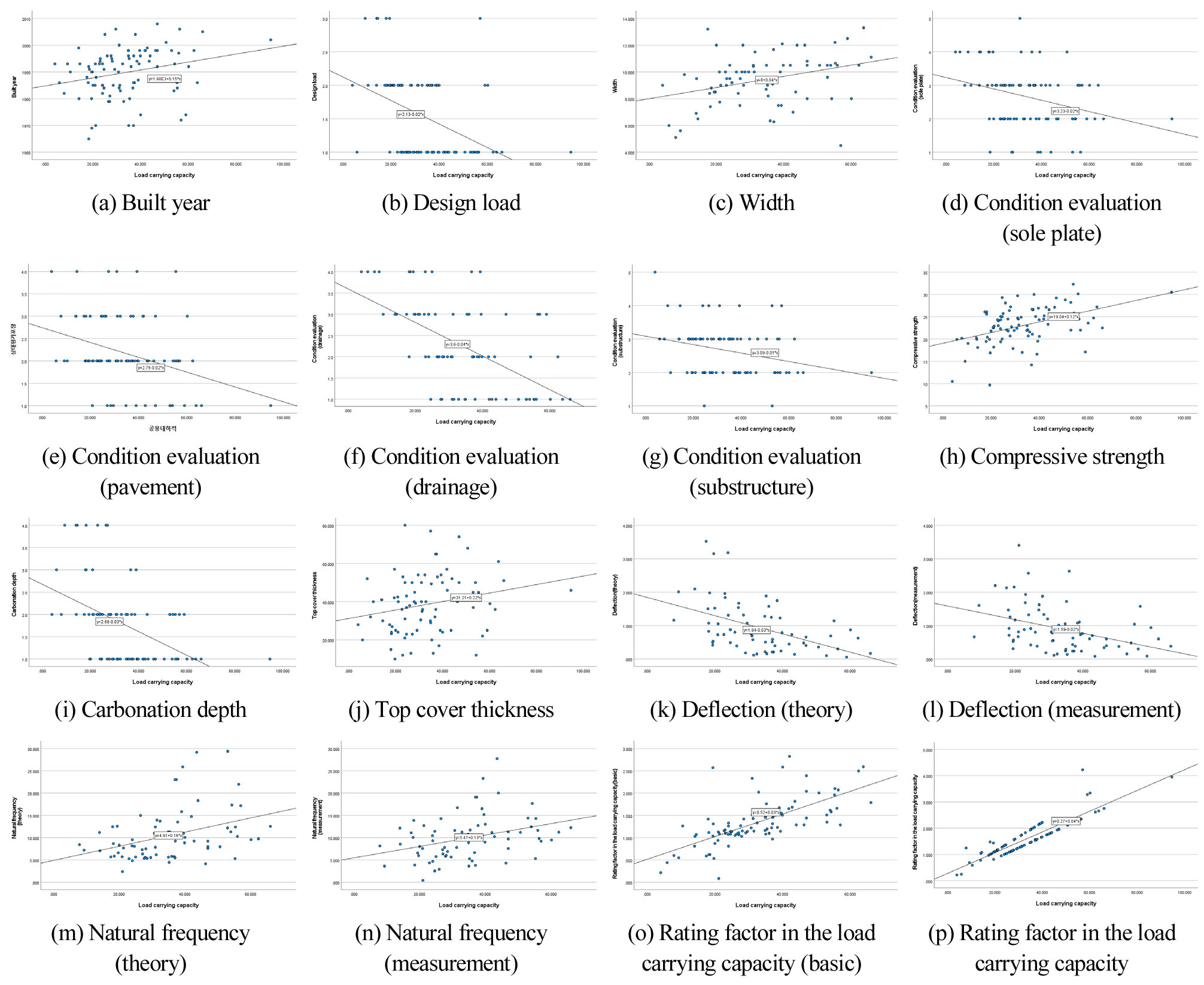
Table 11은 공용내하력에 대한 각 독립변수별 상관분석 결과를 나타낸 것이다. 표에 제시된 16개의 독립변수는 모두 상관계수 ±0.2 이상으로 분석되었으며, 표에 제시되지 않은 다른 독립변수는 ±0.2 미만으로 분석되었다. 재하시험에 따른 처짐량, 변형량, 고유진동수와 같은 계측 데이터와 안전성 평가 자료는 상대적으로 확보하기가 어렵다. 대부분의 재하시험이나 안전성 평가는 정밀안전진단에서 실시되기 때문이다. 따라서, 상관계수가 높은 지표를 발굴하기 위해서는 지속적으로 다수의 데이터를 확보하기 위한 노력이 필요할 것으로 생각된다.
Table 11.
Results of correlation analysis between Load-carrying capacity and independent variables
3. 결 론
본 연구에서는 교량 내하성능 추정 모델 개발 연구의 일환으로 교량의 공용내하력과 독립변수 간의 상대적 영향력을 파악하기 위해 Pearson 상관분석을 수행하였다. 이를 통해, 유의수준을 만족하는 변수들(설계하중, 상태평가(배수), 압축강도, 탄산화 깊이 시험결과, 이론 처짐량, 기본내하율, 공용내하율)을 도출할 수 있었다. 교량의 안전성 평가 자료는 데이터 확보에 어려움이 있어, 제한적인 데이터 사용으로 인해 상관계수가 ±0.4 정도로 비교적 낮지만, 지속적으로 지표를 추가하고 관련 데이터를 수집함으로써 보다 정확한 분석 결과를 도출할 수 있을 것으로 판단된다.
특히, 교량 내하성능 추정 모델 개발을 위해서, 교량의 내하성능에 미치는 영향이 큰 지표를 도출하고 상관분석을 실시하여 사용 가능한 데이터를 구축하는 연구는 지속적으로 수행될 필요가 있다. 현재에도 추가적인 데이터 확보를 위해 자료를 수집 중이며, 추가 분석을 위해 데이터 셋을 구축하고 있는 중이다.
향후, 구축된 데이터 및 상관분석 결과에 기초한 교량 내하성능 추정 모델 개발을 통해, 준공된 교량의 손상 진행 추이 분석, 중장기 보수 비용 산정, 내구연한 예측, 그리고 안정성 평가를 수행하지 않는 제3종 및 기타(종외) 교량의 예방적 유지관리 수행에 활용이 가능할 것으로 판단한다.
