

1. 서 론
우리나라는 교량 시설물의 안전 및 유지관리를 위해 「시설물의 안전 및 유지관리에 관한 특별법」(이하 ‘시설물안전법’이라 한다)(MOLIT, 2021)을 제정하여 시행하고 있다. 교량 유지관리 항목에는 외관상태 조사, 시료분석, 유한요소 해석 등이 있고, 교량의 안전성을 평가하는 내하력 평가가 있다. 내하력은 설계활하중에 내하율을 고려하여 산정한다. 내하율을 정확하게 산정해야 교량의 안전성을 평가할 수 있다. 이를 위해, 교량 점검진단 시, 차량재하시험 및 유한요소해석을 수행하고 있지만, 비교적 규모가 큰 제1종 교량에 한하여, 의무화되어 있다. 많은 수를 차지하는 비교적 중 ‧ 소 규모에 해당하는 교량에서는 내하력 평가가 이루어지지 않고 있다(Lee et al., 2016; Shin et al., 2018). 따라서, 본 연구에서는 중 ‧ 소 규모의 교량에서도 손쉽게 내하력을 평가할 수 있는 방법을 제시하고, 위험 교량에 대해서는 법에서 정의하는 내하력 평가 수행을 권고하도록 하였다. 본 논문의 내용은 기 발표한 논문 ‘교량 안전성 평가 지표와 내하율의 상관관계 분석’(Jung et al., 2023) 이후에 연구 결과를 나타내며, 데이터 종류 및 지표 선정 등에 관한 내용은 상기 논문에 자세히 나타내었다. 본 논문에서는 교량 형식별 내하율을 추정하기 위한 다중회귀분석과 추정 내하율을 통한 내하율 판별 정확도 검증 내용에 대해서 기술하였다.
2. 본 론
2.1 다중회귀분석 개요
상관분석이란 두 개의 대등한 변수(X, Y)간의 관련성을 분석하는 것으로 ‘X값이 크기 때문에 Y값이 크다’와 같이 원인과 결과의 형식으로 해석하지 않는다. 따라서 상관분석에서 유의성 검정 후 유의한 상관관계가 있다는 결론을 얻어도 어느 정도로 높은 상관관계가 있는지를 말해주지는 않는다. 회귀분석은 두 변수의 직선적 관련성을 구체적인 수식으로 표현하고, 예측을 위한 목적에도 사용하며, 하나의 반응변수(Y)와 하나 또는 여러 개의 설명변수(x1, x2, x3, …)간의 관계를 하나의 수식(Y = a + bx1 + cx2 + …)으로 표현한다.
본 연구에서는 여러 속성을 사용한 다중회귀분석을 진행하였고, 공용내하율(Y)과 관련있는 주요 변수(X)들을 파악하고, 그 영향 정도를 검증하였다. 일반적으로 회귀식은 설명변수의 수가 많아질수록 주어진 자료를 더 잘 설명할 수 있게 되지만, 추정된 회귀계수의 숫자가 원래 자료의 수와 같아지면 전체 자료에 대한 요약은 이루어지지 않기 때문에, 적절한 설명변수의 수를 선정하여 데이터의 적절한 요약과 함께 전체 데이터가 가지고 있는 현상을 잘 설명할 수 있도록 해야 한다. 이를 위해 상위 항목에서 진행한 유의성 검정 결과를 반영하여 교량 구조형식별로 1) 전체 속성을 사용한 회귀식, 2) 유의미한 속성(상관계수 0.2 이상, p-value 0.05 이하)을 사용한 회귀식을 도출하여 결정계수(R2 Score)를 비교하고자 하였다.
결정계수는 상관계수와 달리 변수간 영향을 주는 정도 또는 인과 관계의 정도를 정량화해서 나타낸 수치로 회귀 모델의 성능에 대한 평가지표이다. 본 분석에서는 다양한 속성(X)이 공용내하율(Y)을 얼마나 잘 설명하는지 보여주는 지표가 되며, 결정계수는 0~1사이의 범위 값을 가지고 1에 가까울수록 해당 선형 회귀 모델이 해당 데이터에 대한 높은 연관성을 가지고 있다고 해석할 수 있다. 그 외 실제 데이터 표본과 예측 데이터의 차이를 표현해 성능을 검토하기 위한 지표로 MSE(Mean Square of Errors, 평균제곱오차)를 함께 검토하였다. 오차에 대한 지표이므로 MSE값이 작을수록 모델의 성능이 좋다고 볼 수 있다.
2.2 다중회귀분석 상세
회귀분석은 독립변수(X)에 대응하는 종속변수(Y)와 가장 비슷한 값을 출력하는 함수를 찾는 과정으로, 이 함수를 선형으로 가정하고 구하기 때문에 선형회귀모형(Linear regression model)을 활용하여 산출하였다. 수식의 형태는 Y = a + bx1 + cx2 + …와 같으며, 독립변수(x)의 가중치(a, b, c, …)는 이 함수의 계수(Coefficient)이자 이 선형회귀모형의 파라미터(Parameter)라고 한다.
분석은 Python의 머신러닝 라이브러리인 Scikit-learn(linear_model)과 통계분석 라이브러리인 Statsmodels(OLS)을 활용하였다. 최소자승법(Ordinary Least Squares, OLS)은 잔차제곱합(Residual Sum fo Squares, RSS)을 최소화하는 가중치를 구한다. 그러나 계산한 가중치가 어느 정도 신뢰를 가지는지 확인할 수 없기 때문에 전체 데이터에서 다양한 샘플링을 통해 여러 회귀식을 도출하고, 결과를 비교하여 최종 회귀식을 도출하고자 한다.
OLS로 구한 가중치의 추정값은 표본 데이터에 따라 달라진다. 만약 여러가지 다른 표본 데이터 집합이 있다면 이 데이터들을 대입하면서 가중치가 어느 정도 영향을 받는지 알 수 있다. 그러나 현실적으로는 추가적인 데이터를 얻기 어려우므로 기존의 데이터를 재표본화(Re-sampling)하여 여러가지 다양한 표본 데이터 집합을 만드는 방법을 사용하였다. 본 연구에서는 교량 종류별 데이터와 전체 데이터를 각각 10,000회씩 샘플링하여 다중회귀분석을 진행하고, 결정계수가 가장 높은 모델을 선택하였다.
회귀분석 모델을 만들기 위해서는 모수 추정 즉 학습(Training)을 위한 데이터 집합이 필요하다. 이 데이터 집합을 학습용 데이터 집합(Training data set)이라고 하며, 데이터 집합의 종속 변수값을 얼마나 잘 예측하였는지를 나타내는 성능을 표본내 성능 검증이라고 한다. 회귀분석 모형을 만드는 목적 중 하나는 알지 못하는 종속 변수의 값을 알아내는 예측(Prediction)을 위함이며, 학습에 사용하지 않은 데이터 집합을 가지고 종속 변수값을 예측하여 검증해 볼 수 있다. 이를 교차검증(Cross validation)이라고 한다. 교차 검증을 하기 위해 기존의 데이터를 1) 모델 추정 즉 학습을 위한 데이터 집합(Training data set), 2) 성능 검증을 위한 데이터 집합(Test data set)으로 분리하여 사용하였다. 본 과업에서는 데이터 양을 감안하여 Training data set : Test data set = 7:3 비율을 사용하였다.
2.3 다중회귀분석 결과
각 교량별 데이터 및 전체를 통합하여 개별 회귀식을 도출하고, 모델 평가지표를 활용하여 결정계수를 비교한 결과를 Table 1에 나타냈다.
Table 1.
Regression analysis results by bridge type
| Brige type | Number of data | Number of index | Highest R2 | ||
| Total | Training data set | Test data set | |||
| PSC I | 33 | 23 | 10 | 17 | 0.89 |
| RA | 21 | 15 | 6 | 17 | 0.95 |
| RCS | 53 | 37 | 16 | 17 | 0.26 |
| STB | 57 | 40 | 17 | 17 | 0.62 |
일반적으로 전체 속성 17개를 모두 사용하여(총길이, 차선수, 총폭, 최대경간장, 설계하중, 준공년도, 상태평가_바닥판, 상태평가_포장, 상태평가_배수, 상태평가_하부, 동결융해_노출등급, 제설제_노출등급, 비래염분_노출등급, 압축강도, 탄산화깊이, 염화물침투량, 피복_상부) 만든 회귀식의 R2 Score가 높지만, RCS는 예외였다.
교량의 안전성 평가 자료는 데이터 확보에 어려움이 있어 각 교량별 데이터는 21~57 set 정도이고, 전체를 합쳐도 164 set로 데이터 수가 적은 편이다. 제한적 데이터 사용으로 인해 유의미한 속성들의 상관계수가 ±0.2~0.3 정도로 낮지만, 지속적으로 지표를 추가하고 관련 데이터를 수집함으로써 보다 정확한 분석 결과를 도출할 수 있을 것으로 기대한다.
교량 형식별로 구분했을 때, 결정계수가 0.76 이상으로 높게 나온 PSC I형교와 RC라멘교는 동일 지표들을 지속 수집 후 분석결과를 살펴볼 수 있을 것이다. RC슬래브교나 강상자형교(STB)의 경우 결정계수가 0.26~0.62 수준으로 다소 낮기 때문에 추후 점검진단보고서의 다른 지표를 추가하거나, 연관성이 예상되는 보고서 외의 지표를 더하여 함께 살펴보면 더 개선된 결과를 기대할 수 있을 것으로 판단된다. 각 교량별 최종 회귀모델을 Table 2에 나타냈다.
Table 2.
Regression model by bridge type
2.4 내하율 추정 모델의 판별 정확도 검증
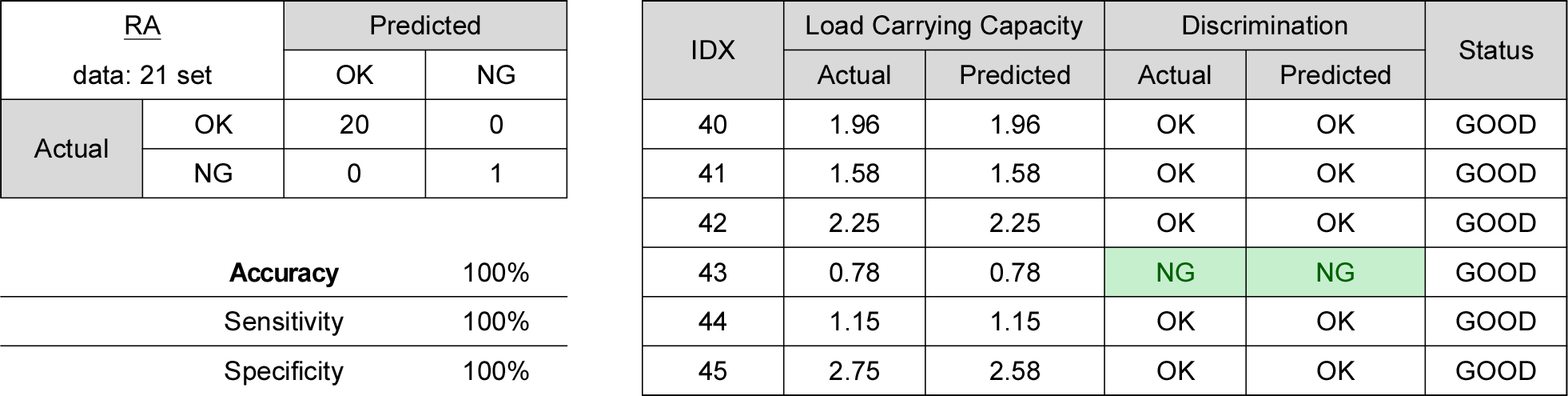
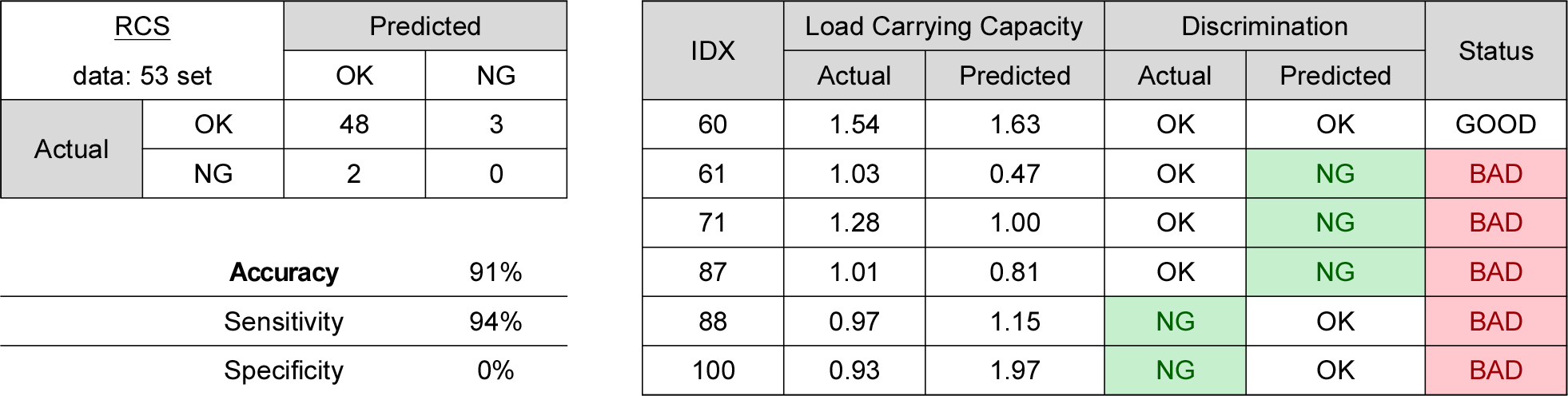
회귀분석 결과에 따라 산출된 회귀방정식으로 교량별 추정 공용내하율을 구하고, 이를 내하력 평가보고서의 공용내하율과 비교 분석하여 내하성능 만족여부를 분석하였다. 내하율은 교량이 안전하게 저항할 수 있는 하중(자중의 효과 제외)과 재하차량에 의하여 발생하는 하중의 비로써 정의되며, 내하율이 1.0 이상으로 산정되었다면 이 교량은 재하차량이 안전하게 교량을 통과할 수 있는 능력을 가지고 있음을 의미한다. 반면에 내하율이 1.0 미만의 값으로 산정되었다면, 해당 교량은 재하차량이 안전하게 통행할 수 있는 능력이 부족하다는 것을 의미한다. 이 항목에 대하여 보고서 내 실제 결과나 예측값이 1.0 이상의 값을 가지면 판정결과를 ‘OK’로, 1.0 미만의 경우 ‘NG’로 표기하고, 두 값의 판정결과가 동일한 상태를 ‘GOOD’, 일치하지 않는 경우를 ’BAD’로 구분하여 분류하였다.
예측 모델을 활용한 결과값에 따라 내하성능 만족 여부를 판별하고, 분류된 결과를 통해 예측 모델 성능을 측정하여 함께 표기하였다. 오차행렬(Confudion Matrix)을 구하고, 정확도(Accuracy)로 전체 관측치 중 실제값과 예측치가 일치한 정도를 구하였다. 오분류 항목에 대해서는 민감도(Sensitivity)로 실제값이 OK인 관측치 중에 예측치가 적중한 정도를 살표보고, 특이도(Specificity)를 통해 실제값이 NG인 관측치 중 예측치가 적중한 정도를 함께 살펴보았다.
교량 형식별 계산한 회귀모델 식으로 정리한 오차행렬 및 평가지표(정확도, 민감도, 특이도)와 특이사항 있는 세부 항목을 정리한 내용은 Figs. 1, 2, 3, 4에 나타낸 것과 같다.


3. 결 론
교량과 같은 사회기반시설물은 안전성이 최우선으로 고려되어야 하는 구조물(Cho et al., 2007; Chai and Lee, 2012)이며, 안전성 평가는 실제 사용하고 있는 교량에 진행하므로 공용내하율이 1.0 미만의 값으로 산정되어 ‘해당 교량은 재하차량이 안전하게 통행할 수 있는 능력이 부족하다’고 판단되는 경우는 극히 적다. 실제 데이터를 확인하면 수집된 164개 데이터 중에 NG 판정을 받은 교량은 4건으로 데이터에서 차지하는 비중이 2.4% 수준으로 매우 낮다.
이와 같이 불균형한 분포의 결과를 가지는 데이터에서는 모델의 성능이 좋지 못하더라도 정확도가 높게 나타날 수 있기 때문에 민감도와 특이도를 함께 살펴보아야 한다. 특히 교량의 안전성과 관련된 지표는 실제 안전성 NG 판정이 나서 재점검을 받아야 하는 케이스가 잘못 판단하여 OK를 받게 되면 큰 문제가 발생할 수 있으므로 민감도와 특이도를 중요 지표로 관리해야 한다.
다만 본 연구의 경우 분석에 사용하는 데이터의 한계가 있어 교량 형식별 NG 데이터가 0~2개 수준으로 민감도와 특이도를 유의미한 수치로 측정하기 어렵다. 전체 데이터를 사용했을 경우는 실측값에 비해 높게 예측값이 형성되는 경우가 많았다. 본 연구의 데이터와 같이 극단적으로 불균형한 데이터에서는 이상 데이터(안전성 NG 판정)를 정확히 분류하는데 어려움이 있으며, 추후 추가적인 데이터를 확보해 나가면 보다 정확한 분석 결과를 기대할 수 있을 것이다. 단기적으로는 다양한 방식으로 데이터를 조정해서 데이터 불균형을 해결하는 샘플링 기법들을 응용해볼 수 있다. 예를 들어 언더 샘플링(Undersampling)은 다수 범주의 데이터를 소수 범주의 데이터 수에 맞게 줄이는 샘플링 방식을 말하며, 오버 샘플링(Oversampling)은 소수 범주의 데이터를 다수 범주의 데이터 수에 맞게 늘리는 샘플링 방식을 말한다. 각각의 방식에 따라 장점과 단점들이 있지만, 현식적인 한계점을 극복할 수 있는 대안들을 함께 검토해 나가면 더 나은 분석 결과를 도출할 수 있을 것으로 판단된다.
